Video
The Importance of Digital Preservation in the Entertainment Industry
8 May 2024
Introduction to Digital Preservation
In the rapidly evolving landscape of the entertainment industry, digital preservation has emerged as a critical concern. As filmmakers and studios transition from traditional film to digital formats, the need to safeguard cinematic holdings becomes increasingly paramount. This article explores the multifaceted nature of digital preservation, its challenges, and the vital role it plays in preserving our cultural heritage.
The Evolution of Digital Preservation
The concept of digital preservation has evolved significantly over the past few decades. Initially focused on traditional photochemical films, the shift to digital media has prompted archivists to rethink their strategies. With the rise of digital technology in production, postproduction, and distribution, the preservation landscape has transformed dramatically.
Digital preservation encompasses not only the safeguarding of digital assets but also the management of physical materials. As the entertainment industry embraces digital formats, the responsibility of preserving these assets falls on creators, studios, and archivists alike.
Understanding Cinematic Holdings
Cinematic holdings refer to the collection of films, videos, and other moving image materials that studios and archives manage. This term encompasses a wide range of formats, including traditional film, digital video, and even newer media forms. As the definition of cinematic holdings evolves, so too does the approach to their preservation.
The challenge lies in maintaining the integrity of these assets while ensuring they remain accessible for future generations. Understanding what constitutes cinematic holdings is crucial for developing effective preservation strategies.
The Role of Digital Asset Management (DAM)
Digital Asset Management (DAM) systems play a pivotal role in the preservation of cinematic holdings. These systems facilitate the organization, storage, and retrieval of digital assets, ensuring that they remain accessible and usable over time. The integration of DAM with preservation workflows is essential for studios aiming to maintain their assets’ longevity.
Moreover, the relationship between DAM and digital preservation is symbiotic. While DAM focuses on the management of digital files, preservation ensures that these files are protected from degradation, corruption, or obsolescence.
Challenges in Digital Preservation
Despite the advancements in technology and methodology, digital preservation presents numerous challenges. One of the primary concerns is the rapid evolution of technology and formats. As new digital standards emerge, older formats may become obsolete, rendering archived materials inaccessible.
Additionally, digital files are susceptible to corruption over time, which can lead to data loss. The sheer volume of digital content produced today also complicates preservation efforts, as it requires significant storage and management resources.
Financial constraints further exacerbate these challenges. Many organizations struggle to allocate adequate budgets for preservation efforts, often prioritizing immediate business needs over long-term archival goals.
The Business of Digital Preservation
The relationship between business and digital preservation is complex. Studios and organizations must balance the need for preservation with the reality of financial constraints. While the long-term benefits of preserving assets are evident, securing funding for these initiatives can be challenging.
Moreover, the economic landscape of the entertainment industry, characterized by mergers and acquisitions, adds another layer of complexity. Rights holders may struggle to maintain control over their assets, leading to potential gaps in preservation efforts.
The Cultural Significance of Preservation
Beyond the financial implications, digital preservation holds immense cultural significance. Films and moving images are not merely entertainment; they are artifacts of our collective history and identity. Preserving these assets ensures that future generations can access and engage with our cultural heritage.
Organizations and studios must recognize their responsibility to safeguard these cultural treasures. This commitment to preservation transcends business interests, reflecting a broader societal obligation to protect our shared history.
The Academy Digital Preservation Forum
The Academy Digital Preservation Forum serves as a vital platform for fostering collaboration and knowledge-sharing among industry stakeholders. Formed under the auspices of the Academy of Motion Picture Arts and Sciences, the forum aims to address the challenges and complexities of digital preservation.
By bringing together filmmakers, technologists, archivists, and other professionals, the forum seeks to promote best practices, raise awareness, and advocate for the importance of digital preservation within the entertainment industry.
Future Directions in Digital Preservation
Looking ahead, the future of digital preservation hinges on several key factors. First, there is a need for standardized practices across the industry. By establishing common protocols and workflows, organizations can streamline their preservation efforts and reduce confusion.
Second, collaboration among stakeholders is essential. The digital preservation landscape is vast, and no single entity can address all the challenges alone. By working together, studios, archivists, and technology providers can share insights and develop innovative solutions.
Finally, fostering a culture of awareness and advocacy is crucial. Educating decision-makers about the value of preservation and its long-term benefits can help secure funding and support for these initiatives.
Conclusion
Digital preservation is a multifaceted challenge that requires a concerted effort from all stakeholders within the entertainment industry. As we navigate the complexities of preserving our cinematic holdings, it is essential to recognize the cultural, financial, and technological dimensions of this endeavor. By embracing collaboration, advocating for best practices, and prioritizing preservation efforts, we can ensure that our rich cinematic heritage endures for generations to come.
Transcript
Chris Lacinak: 00:00
Hi, Chris Lacinak here, host of the DAM Right podcast.
Just a quick note before we get started to say that it would mean the world to me if you rated and subscribed to the podcast on your podcast platform of choice.
Thanks so much, I really appreciate it.
Welcome to the DAM Right podcast.
In AVP’s Operational Model for DAM Success, there are seven components.
Yes, one is technology, the most commonly discussed aspect of DAM.
However, I would argue that the most important component is people.
First and foremost, DAM’s value is in its ability to serve users.
Additionally, what are processes, measurement, governance, continuous improvement, and technology without skilled and talented people behind them?
The central component, and what I would argue is the second most important, is purpose.
Purpose is the fuel that keeps those skilled and talented people focused and driven to produce results and impact.
Today I’m joined by Andrea Kalas, a true pioneer in the field that brings humanity and purpose in abundance.
Andrea’s personal journey takes us from winding nitrate film in UCLA’s “dirty” Film and Television Archive, more on that later, to working on the cutting edge of digital asset management at Paramount Pictures, with stops along the way at DreamWorks, Discovery, and the British Film Institute.
Andrea’s background is not only fascinating, but offers a robust expression of digital asset management fully realized and evolved.
You’ll delight in hearing about Andrea’s personal journey.
But the reason I’ve asked Andrea to join me today is to talk about one of her latest ventures in which she’s serving as project co-chair for the Academy Digital Preservation Forum, formed under the auspices of the Academy of Motion Picture Arts and Sciences.
The mission of the forum in part reads, “With the ascent of digital technology in the production, post-production, distribution, and exhibition of motion pictures, and the concomitant decline in photochemical cinematography and practical disappearance of film projection, we want to engage with those with the greatest stake and influence to ensure that digital preservation is successfully achieved.
Filmmakers, studio executives, Academy members, archivists, operations professionals, technologists, and other practitioners charged with implementing digital preservation.”
Join us as we grapple with questions around defining the entertainment industry today, the business side of digital preservation, and whether we should trust the entertainment industry to take on the challenge of preserving cultural heritage.
And remember, DAM Right, because it’s too important to get wrong.
Andrea Kalas, welcome to the DAM Right podcast.
Thank you so much for being here today.
I really appreciate it.
Andrea Kalas: 02:33
It’s great to talk to you, Chris.
Chris Lacinak: 02:35
I’d love to start just by having you tell us about your background and the path that you’ve taken to get to where you are today.
Andrea Kalas: 02:43
Well, I think, you know, it really all starts with the UCLA Film and TV Archive.
When I was in graduate school at UCLA, I saw a little post on a board, a job board, saying that there was work study positions at the UCLA Film and TV Archive.
And I had come to UCLA to the grad program there knowing about film restoration that was just sort of beginning and knowing that the UCLA Film and TV Archive was there.
So I was excited that it was easy to just get a part-time job there while I was going to school.
And I remember I called and Jerry Golden, who’s a wonderful person still working in the field, was the guy hiring.
And he goes, “You know, this job isn’t, it’s not on the campus.
It’s out here in Hollywood, you know, and it’s a little dirty out here.”
And I was like, “Where do I sign?”
And that time at the UCLA Film and TV Archive was just pivotal for my career because it was, you know, there weren’t programs then.
There weren’t programs in, you know, moving image archiving at that point.
So there wasn’t an option for me to go to grad school in that.
But in a way I didn’t have to because I had people like Bob Gitt, you know, who we used to nickname the Pope of Preservation.
We had Martha Yee, who was incredibly important in figuring out how library science could be applied to moving image archiving.
Literally she was dealing with like early MARC cataloging software that was made for books.
So she was constantly figuring out how to put a square peg in a round hole for moving image materials.
And Eddie Richmond, who was the curator of the archive at that point, who was really figuring out how you manage an archive, how you deal with that.
And Bob Rosen, who was the head of the archive and really a visionary in so many ways in terms of how archives could really intervene in culture in a significant way, in history and the importance of that.
So to me that was incredibly fortunate that I was there at that moment with people who were figuring it out and figuring out how moving image archiving could actually work.
So that’s, you know, that made me really, in my opinion, made me a really good archival professional out of that experience working there.
So yeah, I started off as a work study student and my job was inspecting nitrate.
Nothing that a student would do now.
But it was great.
To me, I loved it, even though it was in these dirty vaults and opening cans, it was a little risky.
But I got to look at all the cans and see like, what is that?
What are these things?
Why don’t we know more about them?
Like that curiosity and the pleasure of archives, which is being near these assets.
And I realized, yep, I’m in it for the long term.
This is what I want.
This is what I want to do.
Chris Lacinak: 05:54
It sounds like you had an all-star team of colleagues there to help you really learn the trade and understand not just the technical stuff, but it sounds like also kind of the value.
Andrea Kalas: 06:03
And they were willing to take a risk on me.
They were willing to, you know, give me sort of more.
So I got offered a full-time job eventually there, you know, preserving newsreels, which was another incredible education because, you know, it was a small thing.
It was still figuring it out.
So I had to do everything from, you know, justifying why I would preserve one newsreel over another with, you know, complex justification.
Then I had to sit at a bench and wind through each newsreel and actually inspect and repair, take it to the lab, see it preserved, then gather all the information together for somebody to catalog it.
You know, so I had to do the whole soup to nuts.
And that was a great.
And the fact that I was just given the rope to do that and figure it out, obviously with everybody’s support and help, but that they gave me that responsibility was just fantastic.
So that was another great, you know, step forward.
Chris Lacinak: 07:02
Yeah, that’s a great start.
So where did you, what did your career look like after that?
Andrea Kalas: 07:06
So after I preserved newsreels for a while, I worked within the UCLA Film and TV Archives Research and Study Center and they had just opened it up.
And it was really the first time where, and a lot of archives were like this at this point, where it was fine to just preserve them and, you know, sort of keep the doors closed, but actually opening it up and providing people to have a place to actually research and watch and, you know, use the archives was relatively new.
And we were on a university campus where these materials could obviously be of great use to students, to researchers, to for classwork.
So we opened up the Research and Study Center and there I really started, and I already had an interest in technology and computers because, you know, universities were some of the first to get computers, you know, so we’re talking about mid 80s, late 80s here, right.
So early on.
And so I was already fascinated with them.
And so, you know, the idea that we could use computers to help with providing access to materials that’s carried, you’ll see that carried through my entire career.
And so we did this project where there was a communications professor who had taped news materials off the air for years.
So he had decades of these materials.
And the only thing that was there was like CBS News on March 2nd.
You know, that’s all the information we had about what was on the recordings.
So we did a project around because we taped a lot of stuff around Tiananmen Square.
We did a project where we actually took the closed caption broadcast signal off the tapes and dumped them into a database so that people could search over terms and things like that.
And and that’s something that’s very common today.
And we see that all the time.
It’s used in all sorts of different search technologies now.
But that was early on that we were sort of.
Chris Lacinak: 09:07
That was groundbreaking.
Andrea Kalas: 09:09
It was big.
Yeah.
So I did a presentation on that at the Association of Moving Image Archivists.
And there was a woman who named Karen Weber, who had been part of AMIA for a while.
And at that point in her career was working with the company CGI that made, you know, you know, visual effects, software and hardware.
And they were working with DreamWorks and they wanted to create a digital archive for animation.
And so she said, oh, this person has a kind of idea about how technology and archives can work together.
Let’s, you know, let’s recommend her for this this job at DreamWorks.
And so that’s that’s how that happened.
I went from UCLA to DreamWorks.
And it was that was another.
Chris Lacinak: 10:08
It had to be a pretty big cultural shift.
Andrea Kalas: 10:10
That was that was like, whoa.
Yeah.
I went from, yeah, just sort of university to Hollywood.
And and it was that was fascinating.
Absolutely amazing.
I mean, I was an archivist hired before there was anything to archive.
Yeah.
Right.
That’s, you know.
And so helping create a digital archive from nothing for animation was just was fantastic.
And I just you know, I just spent my time getting to know all about animation, which was fantastic to get to know and the complexities of that and getting to know the artists and how it worked and how animation worked and how that, you know, animation it was really sort of also almost production assset management.
Right.
They needed an archive during production.
But we were also figuring out how then to have these kind of off ramps from that into a more, you know, sort of long term repository.
And also I was looking at collecting up actual physical materials like all the backgrounds were painted, you know, so and they’re unbelievably beautiful.
But, you know, works of art, making sure that we, you know, handle those well and archive those well as well.
And also in those early days of DreamWorks and was DreamWorks was going to be this huge studio, right?
It was going to have it was a music area.
There was television.
There was so starting to actually become go outside of animation and build an archive for all of those things.
So so that was fantastic to be able to do that from scratch, from nothing.
Right.
Build it out of nothing when things can be ready when the materials actually came into our.
Yeah.
So and and and be around just amazing technologists, too, because animation’s always been on the forefront, certainly of entertainment technology.
You know, they’ve always been the ones who have been out there first figuring out file based workflows, figuring out, you know, I mean, you know, great stuff.
Like I remember, you know, we were going from physical ink and paint to digital ink and paint.
So that was being that was a transition that was happening while we were making a movie, which was amazing.
But one thing I remember so clearly was like when the you know, with physical ink and paint, you had to keep a cap on the number of colors you would use because you needed to have a set number of colors that everyone would consistently use.
You had to keep those paints the same color.
Right.
You couldn’t you know, and all of a sudden with digital ink and paint.
You could have this whole all sorts of different palettes that came out.
I remember the animators heads kind of exploding a little bit like, oh, wow, this is so different.
When technology was cool.
Right.
It’s like when technology was our friend, you know, it was really that era of, you know, the sort of expansiveness of how it could support, you know, creativity.
So that was so fun to be around.
Chris Lacinak: 13:23
Was there any production that you recall specifically while you were there that was in that transition point into this?
Andrea Kalas: 13:31
Yeah, it was the Prince of Egypt was the first big movie that we were working on.
Chris Lacinak: 13:36
Okay.
Andrea Kalas: 13:37
And it’s a beautiful, beautiful film if you ever get a chance to watch it.
You know, it’s basically it’s the Moses story.
It’s a Ten Commandments story, but in animation.
And you know, just I think that was what I, you know, remember so fondly about it is just the beauty of it and how how much artistry there was in watching that happen.
It didn’t turn out to be the most, you know, the most popular of the early DreamWorks animated films.
You know, Shrek came along closely thereafter.
That was a huge, huge moment.
Interesting.
Yeah.
But but Prince of Egypt was really a rallying point for everyone that worked there in the beginning and how, you know, because we were figuring out the entire pipeline, the workflow, everything as the movie was being made.
So and, you know, it really bonded that group of people, we’re still friends with a lot of those people to this day.
Yeah, it was such a unique, you know, environment.
And what was great for me was, and I think for everyone there was, you could talk to anyone.
You could walk into anybody’s office, any artist, any animator, any executive anywhere, any time.
And anybody would and everyone was really sort of collaborative.
In fact, there were no titles.
That was a big thing.
Interesting.
Early DreamWorks.
Yeah.
And so that was just great for somebody who was trying to just absorb as much information as possible.
Right.
Yeah.
It was a wonderful atmosphere for that.
Chris Lacinak: 15:09
It’s kind of it’s kind of mind blowing to think about, like, at that point in time, the difference in tools, infrastructure, like capabilities, like it’s pretty wild to think about that you were tackling, beginning to tackle those challenges at that point in time.
Different world, different world from today.
Andrea Kalas: 15:28
It wasn’t, it wasn’t.
I mean, I still deal with some of the same issues today.
You know, just sort of, I think, you know, what, what archives and animation have in common is that they have to have a lot of structure.
Right.
And that was where I, you know, sort of find a common core.
Right.
So when you build a pipeline for animation, you have to have a pretty strict file naming convention or, you know, for every sequence scene shot, you know, it because everyone shares and collaborates, goes through a number of departments.
So that tight structure is absolutely necessary for animation to work.
Right.
And so that’s very good for archives.
Yeah.
We like that.
Chris Lacinak: 16:15
And digital asset management.
Andrea Kalas: 16:16
We like structure because then we know what we’re, knowing what we have.
Yeah.
So that was, that was interesting, you know, meeting of the minds.
Chris Lacinak: 16:24
I see that.
And so where, from DreamWorks, what was the next step in your career there?
Andrea Kalas: 16:31
So one of the things I did at DreamWorks was we figured out that, you know, even though the movie takes three years, people need access to materials during that, like marketing and consumer products and things like that.
So these off ramps we created from production into archives also had different approval steps and things like that.
So that, and we actually built out an access portal for people that needed materials into the production.
Okay.
And then I gave another presentation at another Association of Moving Image Archivists conference about this concept of sort of in production archiving and Discovery saw that and they were interested in trying to expand on that because they had the same issue was more around making both a domestic and an international version of some of their big, big programs that that wasn’t enough time for them to do that.
So then I worked for Discovery for a little while and we did that.
We had actual video loggers on set, the logging, some of the videotapes that were being directly after they were shot, put them into a system so that the international people could have access to those materials and create their show.
And we were going to ramp that up a little further and then the bubble burst, right?
And so that program was sort of seen as a luxury rather than a necessity.
And so Discovery, so I sort of moved away from that a little bit and I worked sort of with their stock footage group and things like that.
But it wasn’t the sort of cool program I was hoping to do.
But we did some really great things.
Like we actually had a really early digital dailies system where people could, from their shoot, put this like postage stamp sized little video on the world wide web so that executives could take a look at it.
We had all sorts of bandwidth constraints and problems with that, you know, but we did some really great stuff just sort of experimenting with technology.
Chris Lacinak: 18:42
the dot com bust of the early: 2000
Andrea Kalas: 18:46
Yeah, the dot com.
Chris Lacinak: 18:48
So yeah, that was nascent stages of digital asset management as we know it today, right?
That was the early, I remember coming out to Hollywood and doing the early digital asset management conferences that now I think it’s a Lowes.
It was something else back then.
But anyway, yeah, that was a very exciting time.
Everybody was all psyched up about the possibilities.
Andrea Kalas: 19:06
Yeah.
And right.
And some of the tools for digital asset management were starting to come out.
The video logger we used was out there.
There were other tools that were just starting at that point.
So yeah, trying to understand where they were, you know, and they were really early and they just had some functionality, but trying to work with them.
It was an interesting time.
Chris Lacinak: 19:30
Wow.
Okay.
So UCLA, DreamWorks, Discovery, or Discover.
And then, not Discover, Discovery.
Discover is a credit card.
What next?
Andrea Kalas: 19:42
Then the British Film Institute.
So then I was just, you know, I found out that, you know, that was the position, head of preservation was coming open and that I might have a shot at it.
And that was fascinating to me, right?
To be able to work in such a huge archive, work in a European archive, work with an enormous collection.
So that was an opportunity I didn’t want to miss.
So after, you know, a long time of applying because I was American and it was a British job, I finally, I got that position.
And that was, that was an incredible, you know, that was like a, so here I was with all this high tech stuff, you know, and I go over to the BFI and it’s like, oh, okay, I’m going to go back a couple decades here.
You know, there’s a film lab, very analog.
There’s not much digital anything going on.
And so that was really my job was to transform from analog to digital an entire conservation center.
And that was great too.
It was wonderful.
It was, there were so many great colleagues to work with and try to figure out how to manage things and even retraining people and, you know, because people weren’t even, they weren’t even scanning film yet, right?
They had to get a film scanner.
It was all photochemical.
But it also brought, got me back to my experience from UCLA because I had to deal with photochemical film and photochemical preservation so that it was a great way of, and also I really loved getting back with, with film too.
I have a, you know, connection to movies, I think a little bit more than I do to TV.
But even though I love TV, I work with TV all the time.
I love TV, don’t get me wrong.
TV is great.
But I think it was just more, you know, it’s more interesting to me.
Yeah.
Chris lacinak: 21:45
So you were, you must have been the perfect candidate at that time to bring that mix of skills you had that in-depth hands-on film experience and all of the most modern digital technologies and stuff.
So yeah, I can imagine they looked at you and said, this is the perfect person to come and transform this operation.
That must have been fun.
Andrea Kalas: 22:03
It was a lot of fun.
And it was just incredibly, and not only working with amazing colleagues at the BFI, who I’m also still very close to and still call for, you know, like my colleague, Charles Farrell, who was much more in the, he was a television engineer.
And we used to have these debates all the time, you know, it was sort of film versus television, you know, because they used to be very separate technologically.
Now they’re not, right.
And so just sort of arguing over approaches of preservation, things like that.
They were great.
They were, they were good arguments.
And I still will call them up and argue with them.
Chris Lacinak: 22:44
Hopefully there’s some hellos before the argument starts.
Andrea Kalas: 22:48
Oh yeah, no, no, no.
We’re great, great, great, great friends.
Wonderful friends, you know, I respect him enormously.
So they’re always very, you know, fruitful, fruitful arguments.
That’s great.
So you know, and also just being in Europe was great too, because there were lots of, because that was before Brexit.
So the UK was still involved with, yeah, so with European initiatives.
And so for example, I got involved with, there was a European metadata standard for cinematographic works.
And so, you know, and so I got to be involved with that and worked with people from Germany, France, the Netherlands, you know, on putting together a metadata standard for film, which then got implemented and required by any EU funding and still stands today.
So that was great too, to be involved with those kinds of things and learn a lot from really, really smart people across Europe as well.
So it was not, it was both learning from colleagues in the UK and being involved with, you know, a sort of different approach to, or a rigorous approach, I would say.
Because European archives are really, their client is their government, right?
Because European films and television programs are often funded by the government, that, you know, there’s just, there’s sort of, there’s a closeness to the archives and their funding agencies from the government.
That means, in a way, additional rigor, right?
You have to prove that what you’re doing is really good.
They take it seriously.
So that was a great education as well, in being in that environment and how to really be rigorous about justifying what you’re doing with an archive, transparency about what you’re doing, you know, how to make sure that what you’re doing really makes sense and is both, you know, obviously costs are an issue, but also, you know, what you’re doing is absolutely the best or the right thing to do.
You know, people would research that intensely.
You know, we built a whole new vault while I was there.
And you know, and that was a 25 million pound, you know, investment.
To build a cold vault meant we went into, you know, intense, it was like a five year project of getting-
Chris Lacinak: 25:28
Yeah, it’s a big deal.
Andrea Kalas: 25:29
Experts from around the world to say, “Why is this temperature and humidity the right one?”
Lots of different, so, but getting that, that’s what I really appreciated that exercise, because it gave me more expertise and it taught me how to be rigorous and do it well.
Chris Lacinak: 25:54
If we fast forward to today, can you talk a little bit about what you’re doing today?
Andrea Kalas: 25:58
So I came back and when I was, heard about the job at Paramount Pictures and I was always interested in working in a Hollywood studio.
I thought that would be, you know, and be the archivist for a Hollywood studio was always interesting to me.
And so when that job came up, I was definitely interested and came back to that.
And so, and I’ve been there for 15 years, which seems amazing to me.
And it’s just been an incredible experience because we had the support of an incredible executive team that also took it seriously.
So, you know, we, you know, we did a, launched a preservation program.
We built out a digital preservation infrastructure.
We’re now working really hard on how, you know, AI and ML can provide discovery to our assets.
So, you know, it just gave me the opportunity to do a really good job and have great colleagues too that are, have made the archive great.
The other great thing about Paramount Pictures archive is that everything’s under one roof.
Different studios will have an archive here, an archive there, but we have stills, props, costumes, music, all the film and tape all under one place.
And more recently, now that we are Paramount Global, I’ve also started taking on CBS archives and the Viacom brand archive.
So expanding that a little bit more.
So that’s why I’m hoarse.
It’s a lot of work.
But it’s all good.
It’s all great.
It’s all, you know, finding ways to preserve and make accessible all these incredible films and television programs.
Chris Lacinak: 27:52
You have digital asset management is in your title.
From this conversation, I would think that you probably like we do for this podcast and the work that we do use a pretty broad interpretation or definition of digital asset management to encompass digital asset, what people traditionally think of as digital asset management, but also digital preservation and digital collections management and those sorts of activities as well.
Is that right?
Andrea Kalas: 28:16
Yeah, I think digital asset management is in my title.
You know, and actually, you know, I sort of go back and forth between asset management and archives because it is sort of, you know, that’s the way to describe.
But I think within that phrase, digital asset management, I think what I interpret that is and I think that means is that you take seriously the fact that you have digital assets, whether it’s a moving image, an image, you know, a document, whatever it is, and you have thought very seriously about how you’re going to make sure that those are around and accessible to your clients.
You know, and your clients can be anybody, right, depending on what kind of organization you are.
An archive is never its own thing.
It always has a client.
My client now is the corporation, right?
The people that work for Paramount Global and all the business units, whether it’s Home Media or Marketing or Theatrical.
Those are my clients.
Right.
When I was in the BFI, my clients would have been the British public.
Right.
So, but every but you need to make sure that your digital asset management system is serving your clients.
So it’s so it’s digital preservation is part of that in in Paramount Pictures because we continue to distribute our films over and over and over and over again.
Right.
So we will hopefully be distributing Godfather for another hundred years.
Chris Lacinak: 29:53
Right.
So Paramount Pictures wants to leverage those assets for as long as possible.
Andrea Kalas: 29:57
We will.
Yeah.
So making sure that preservation is part of it is serving my clients as well as providing access.
So that’s you know, so yes, the the software, the hardware, the functionality, everything that goes into digital asset management is is driven by what what that archives role is within their organization.
Chris Lacinak: 30:18
I want to talk a little bit about you’ve got a theory.
I’ll call it a theory.
I don’t know if you would call it a theory around the relationship between library science and rocket science that I think would be interesting to interject here before we jump in.
Would you mind talking about that a little bit?
Andrea Kalas: 30:32
Yeah, because as we talked about earlier, my experience at UCLA Film and TV Archive and seeing the brilliant minds of Martha Yee and and her team to actually figure out how to create an inventory system for moving image archives and how to really categorize different types of materials.
I mean, this was, you know, this was before any of the protocols that are out there now that people can follow, right, that people do follow for making sure that they’re using the right metadata schema or thinking about what things are considered preservation assets versus reference assets.
None of that was there was no there was no blueprint for that.
And so being around that and knowing that that came from intense research into library science, you know, Martha Yee had a Ph.D. in library science and other things like that, that that that background of the people that first figured out that card catalogs were going to go away if we needed a computer based system and how to classify things and how to work things at this such an important part of the history of technology when it comes to digital asset management.
That you know, and I just think it gets doesn’t get as much love as it should.
So that’s why I talk about library science and rocket science must work together, because I think we we think about sort of the cool stuff, the latest, you know, video format or other sort of cool technology advances which are there, not not short shrifting them, but, you know, to just, you know, pay homage to incredibly hard work of lots of library scientists that have gone before us to to figure out how to build good digital asset management systems.
That’s what I that’s what I mean by that.
Chris Lacinak: 32:32
Thanks for that.
I want to maybe we can touch on terminology real quick.
You have used the term moving image.
We will talk about there’s there’s terminology used in the forums website around cinematic holdings.
We’ve talked about film, we’ve talked about video.
I’d like to parse those a little bit or maybe put some definition around them so that folks listening understand what we’re talking about.
So we talked about moving image, we’re talking about anything with a moving image, video or film.
Tell me tell me if you disagree with any of this.
Andrea Kalas: 33:05
Yeah, no, that’s right.
It’s a catch all for for anything that moves right
Chris Lacinak: 33:09
So Association of Moving Image Archivists is a catch all for all of those things.
Andrea Kalas: 33:13
Right.
Chris Lacinak: 33:14
The one that I wanted to ask you about was cinematic holdings.
Should we think about that as all film?
Should we think about that as film only produced with the intention of being going through like cinema, commercial cinema sort of thing?
Or how do you think when you talk about cinematic holdings?
How do you think about that?
Andrea Kalas: 33:30
Good question.
I mean, I think, yeah, it is is your question is basically, does it mean that film is only it’s something that actually gets released in the theater?
And I think that’s increasingly not true anymore.
Right.
Because of streaming.
But also, for example.
One of the things that when I got to the BFI, that was amazing.
They had discovered was these early portrait photographers had gone to factory gates and other places where people would come in and set up a camera and then held up a sign said, come and see yourself on the screen later.
And then they would go to a church or a hall of some sort and show these back.
Now, that’s not a proper theater, but I would argue that cinema, you know, so it’s you know, yes, I do think that there is a you know, it’s getting closer and closer.
Like what is a what is the difference between a movie and a TV show now?
Very hard to differentiate.
So but I think that, you know, cinematic holdings still have relevance.
You know, there’s the obvious ones, feature films or films that were distributed in theaters.
And then there’s other things like documentaries or other things that were one piece that are filmic.
I mean, I think the you know, the work that I’ve done with the Academy is based on the fact that Academy is is about film.
It’s about cinema.
It doesn’t, you know, deal with television.
And so even though those those things are melding and becoming closer and closer together, I think there’s still there’s a difference.
Chris Lacinak: 35:13
Is it fair to say that to the extent that there is a distinction between film and cinematic holdings that the work of the Digital Preservation Forum is, you know, if not 100% than 99% relevant to anybody with film and other moving image holdings?
Or is that an inaccurate statement?
Andrea Kalas: 35:35
Yeah, I mean, we’re highly aware that, you know, especially when we’re dealing with digital preservation and the technology associated with it, that, you know, the kinds of things that we’re talking about could absolutely apply to things that were in episodes as well as a long form, right?
So nobody’s tried to fool themselves that it’s only about things that call themselves cinema.
But that’s what, you know, the Academy of Motion Picture Arts and Sciences is mostly focused on, right?
Right.
So that and that’s who’s sponsoring that.
But you know, there is, you know, there is, we’ve had several conversations with the Television Academy, right?
They have a similar group, a Science and Technology Council.
And so, you know, I could see, you know, one day where there’s a much more high collaboration between the two around digital preservation.
Because yeah, the concepts definitely overlap.
Chris Lacinak: 36:29
Are you liking this episode?
It would mean a lot if you let us know by rating and subscribing on your podcast platform of choice.
Looking for amazing and free resources to help you on your DAM journey?
Let the best DAM consultants in the business help you out.
Visit weareavp.com/free-resources.
And stay up to date with the latest and greatest from me and the DAM Right Podcast by following me on LinkedIn at linkedin.com/in/clacinak.
Chris Lacinak: 36:58
I’ve kind of jumped the gun a bit because I’ve started to talk about the forum already.
Would you, I guess, let’s just say that you are the Project Co-Chair of the Academy Digital Preservation Forum.
Given the background we just heard, that makes all the sense in the world.
But maybe you could tell us a little bit about how you came to be the Co-Chair and tell us a bit about the work of the forum.
Andrea Kalas: 37:22
Yeah.
So I was on this when I got to be a member of the Academy, I was accepted as a member of the Science and Technology Council.
And one of the reasons I wanted to be part of that council was I wanted to advance the concept of digital preservation, have it taken more seriously.
lemma back in, I think it was: 2007
And it was the first step, but it also said that it was really expensive to do digital preservation and we weren’t ready yet.
And I thought we needed a better message.
So that was really my mission was to say, you know, actually, lots of people are working on digital preservation and it is possible and we need to make sure that we’re talking about it well.
And so that was really my mission by joining the Sci-Tech Council.
And so the committee, which I think was like Digital Preservation Committee or something like that, came up with the idea.
We were going to do a big event and then follow that up with a website, but then COVID happened and then we focused on the website first.
And so the website really is, it is a forum.
It is a place for people to go.
There is an area on the website where anyone can post anything, have discussions and things like that.
That is the purpose of it, to understand that there are real complexities when it comes to digital preservation, to have a place where people can watch some videos about different topics around digital preservation, to comment, to add new articles, to however they are, to have a place where whoever you are, even though it’s very much, you know, from sort of an Academy standpoint, so entertainment industry based, cinema based, still, I think it’s open enough for anybody that’s interested in digital preservation, especially moving images and digital preservation in general, to have a place to go and learn more and hopefully, you know, sort of talk amongst themselves, train each other on what the best practices are so that we can continue, you know, to have good digital preservation of so many movies that are created digitally, that are really great works of art that need that kind of attention.
Chris Lacinak: 39:55
that came out, I think it was: 2007
And I wonder if you could just give us a background around that.
So maybe tell us, you know, for folks that aren’t acquainted with film, maybe just explain a little bit more when you say photochemical, what you mean.
And then could you give us a brief history of like how that’s evolved and where we are today with the film versus digital on the preservation front?
Andrea Kalas: 40:53
You know, it’s interesting.
It takes me back to, you know, when I first worked at UCLA and we had this rallying cry, “Nitrate won’t wait,” right?
o deteriorate before the year: 2000
And so dutifully, many archives did put it on to acetate film, which then we discovered also deteriorates really quickly.
But you know, it’s interesting, like that time was film wasn’t really a trustworthy source in a way, you know, that could deteriorate, that was scary.
Fast forward to now where film is like, that’s the answer, right?
It’s still, people are now suspicious, very suspicious of digital.
And so I hear this all the time, like, why?
Just preserve it on film?
What’s your problem?
You know, that’s work, that’s the archival standard, that’s what we should do.
And you know, I just don’t think it’s that simple.
You know, there’s, for example, you know, audio, there’s not really that well, great of a way to preserve audio that’s digital onto some sort of photochemical format anymore, right?
That technology is starting to, it’s sunsetting.
Mag isn’t made anymore, it’s not there anymore.
There are things that are really inherently digital, like effects that need to be treated digitally.
And so I think that that feeling, it’s something that I always encounter and a lot of people will push back on that.
You know, I remember sitting in the room with the then president of the Academy, John Bailey, who said out loud, you know, isn’t digital preservation an oxymoron?
So there’s always been this very big concern that digital is not trustworthy for the long term, that, you know, it’s going to go into the ether and things like that.
And that’s the biggest, one of the biggest challenges for digital preservation.
How can you be a trustworthy guardian of assets in your asset management system?
And I know it’s something that all of us have to manage on an ongoing basis because it’s not, you know, I think there’s a perception that you put a piece of film on a shelf and everything’s fine.
Well, actually, that’s not necessarily true.
You still have to have a really good vault.
You have to maintain that vault.
You have to make sure that you re-can that film, possibly occasionally.
You have to have archivists to make sure your inventory is okay.
It’s not without its own maintenance.
Same with, and with digital, it is more complicated.
There’s a lot more, but it’s, I think it’s, it’s the unknown and not knowing and not enough people knowing how to really dig in and insist with their technology partners to put this functionality in, et cetera.
When we did our digital preservation infrastructure at Paramount, I had a lot of, again, good battles and arguments with the infrastructure team, the people that oversaw network and storage, because I wanted to know where within that storage system that asset lived within my digital asset management system.
And I wanted to set up annual health checks automatically.
And that involved people that dealt with infrastructure systems that were really opaque and asking them to make them more transparent inside a digital asset management system was something new to them.
So I think that’s part of it as well, is that it’s that understanding of what you need for digital asset management system to make it trustworthy, to make it robust.
I think the more people become educated by that, and frankly, the younger the colleagues are in this space, I think that will become more of a, and it already has, there’s already plenty of really smart people doing this in our field.
So I think that’s the, that may be the tension about photochemical versus digital, but it still exists.
It hasn’t, it’s still a concern and it still is there.
And you know, and this binary approach of either or is the other silly part of it, right?
I love film.
I built two great film vaults that are the best they can be so that I can preserve that original film.
I love seeing beautiful print made in ideal conditions.
You know, my passion and my affection for film is alive.
Just because I like digital preservation and also appreciate films that were made digitally doesn’t mean I started hating film.
And you know, so I think that’s the other thing is sometimes people, that either or thing is…
Chris Lacinak: 46:17
You have to hold two thoughts in your head at the same time.
Andrea Kalas: 46:20
Yeah, like, yeah, we can do that, you know?
And so I think it’s interesting.
And so it’s something that it’s just an ongoing, it’s awareness, it’s understanding, and I think it’s trust too.
Trust in archivists and institutions to handle digital objects well.
And maybe we need to do a better job at showing that it’s possible and it’s done every day across tons of industries.
You know, maybe that’s our job in this space to show we are trustworthy repository advocates.
Chris Lacinak: 47:02
So is Paramount Pictures an aberration in the entertainment industry as far as the embracing of digital preservation?
Or is that the norm these days?
Andrea Kalas: 47:11
Not at all, no.
And that’s one of the wonderful things about building up the site, the Academy Digital Preservation Forum, was I decided to, you know, as…
Wanted to build a site that was going to have content and who was going to be my sort of editorial board for that content, right?
And so I assembled people from Warner Brothers, Sony, Fox, now Disney, to be that group of people.
We called it the Curatorial Working Group.
And they’re all listed on the site.
So I would bring these topics to that group.
It was one of my…
The best parts of the pandemic, it was like every Friday we had these discussions about, you know, and it was this chance for us to really discuss these issues between ourselves and show that across that group, the sort of studio group, that there were a lot of really best practices.
There were a lot of things that people really take seriously about digital preservation.
So, you know, and that was…
So that’s what the site also represents, is that collective thinking and considered approach to digital preservation.
Chris Lacinak: 48:27
I can see that being useful for sure.
Let’s sidebar on another kind of terminological thing here.
I think I use the term entertainment industry.
How do you think about who the entertainment industry is today?
When I think about it from my perspective, yours obviously in it, as I’ll call myself an outsider, the blurring of lines between both the, you know, entertainment industry versus big tech, as well as just like the blooming of the entertainment industry across the globe, right?
We used to think of entertainment industry really being Hollywood centric.
Now there’s major cinematic industries throughout the world.
How do you think about who the entertainment industry is today?
Andrea Kalas: 49:14
I mean, first and foremost, I think that, you know, the sort of the traditional studios, the big studios have definitely been challenged by the streaming services, right?
By Netflix and Amazon and now Apple.
And so that’s the biggest challenge to that model, right?
And that’s, they are definitely part of the entertainment industry now.
So that is where that it’s definitely, that’s where our entertainment is funded and made and those, you know, that’s, that is, you know, sort of the biggest industry just in terms of sheer output, right?
That those streaming services have met the studios at that level.
You know, so that’s, that’s one part, but yes, there’s, there’s every country has, you know, some sort of entertainment industry of their own, right?
So that’s the other wider part is that, you know, we know more and more about, you know, international output than we ever had before, which is exciting, right?
We’re not, we’re not in a world where American entertainment industry is the only industry anymore.
So that’s, that’s the other part of the global.
And then beyond that, of course, there’s people that are creating entertainment every day with their cell phones, right?
You could say, you could argue that that sort of, you know, web 2.0, , 2.5, 3.0, whatever entertainment industry, right?
Of TikTok and Instagram and everything like that.
That’s arguably an industry in and of itself.
So so it’s, you know, yeah, it’s, it’s certainly not the big five studios making movies and everybody else has to bow down anymore at all.
You know, it’s changed massively.
Chris Lacinak: 50:59
Let me ask another question that kind of dives into maybe more of the traditional big five or, you know, traditional entertainment industry.
In my experience, what I’ve seen, and this is, I’m thinking here about kind of the distinction between rights holders and ownership versus who holds the physical materials or digital materials on their servers.
What I’ve seen is that through mergers and acquisitions, transfer and ownership of collections, that oftentimes the physical materials may have never actually gotten inventoried and moved.
So something that’s owned by one entity, A over here, who is leveraging their ownership, they’re licensing it out.
The physical materials or the digital files may live still at the previous entity who held it.
And it seems like in a lot of ways, those business, there’s just been a collegiality.
Hey, oh, we have this thing, you know, do you have it?
Can you send it to us?
That has made that okay.
It hasn’t been, you know, in the short term for the purpose of doing business, that seems to be okay.
But when you think about digital, well, preservation period, whether it be digital or physical, that seems problematic.
And I don’t know, you know, is that, is that problem so small as to be negligible or is that a larger problem that exists out there that has to be grappled with?
Andrea Kalas: 52:17
It’s really interesting because sometimes I think, okay, when the all world’s archives are digitized, right?
And perhaps they’re, you know, sort of available in the cloud or on some sort of on-prem server storage that, you know, you could really just hand the keys over, right?
You don’t have to move the assets anymore.
Right?
And yet we do, we do move, we do, you know, Paramount had Marvel for a while, you know, when Disney purchased Marvel, we went through an enormous project of, you know, identifying all inventory and moving all inventory digital and physical over to Disney, you know, I have a binder like this thick of everything we, you know, went through to do that.
So it does, it still does matter that where your holdings are, but to your point too of, you know, other material, different libraries owned by different companies.
It doesn’t make sense.
Paramount movies made between: 1929
Paramount owns the Republic Library, you know, Warner Brothers has RKO, early MGM.
So there’s, you know, different library acquisitions make it a little more complicated too.
But yeah, I still, I think, you know, I’ve not worked with people.
I’ve always known that we get the materials when we need to distribute them.
I’ve not had that experience that you’re talking about.
Chris Lacinak: 53:45
I don’t want to start spreading rumors here.
Maybe I’m…
Andrea Kalas: 53:48
No, no, no, it’s fine.
I’m sure it happens.
It’s just not been my experience.
Chris Lacinak: 53:52
I guess that just made me think about like the, that this term about entities that have cinematic holdings may have cinematic holdings that, you know, in partial or in whole may or may not have rights to actually leverage, which brings in like the business angle.
Right.
And I guess I wonder, you’ve given us some great insights into the complexities around some of the technical things around digital preservation, but what the forum makes clear.
And I think what those digital dilemma made clear, and at the same time there was the Blue Ribbon Task Force on Digital Preservation, Digital Preservation, Sustainability and Access, something like that.
They all focused on the business side as being like, I think maybe the main driver.
And I wonder what’s your assessment of what the business complexity looks like with regard to digital preservation.
You’ve touched on it a bit, but can you give us in the same way you’ve given us some insights into the technical complexities, like what is the business side look like of digital preservation?
Andrea Kalas: 54:52
Well, so, you know, again, I look at what’s my role, right?
So my role as an archive for Paramount is to make sure that I’m preserving the materials for which we have what I call substantial rights.
That’s my phrase.
I made it up.
And so that means if there, we have rights worldwide in perpetuity, all media, then that’s a movie I’m going to preserve.
If we have rights in the US only, but it’s also forever, yeah, that’s worth it.
Because my company, you know, can benefit from that long-term holding of that physical, of that materials, right?
So we might acquire something for two years and distribute it, and then it goes back to a rights holder.
I’m not going to preserve that.
That’s somebody else’s property, right?
So it really is based on ownership.
And I do think, you know, and that’s where my focus is.
And I feel that’s an obligation of rights holders too, to look after the materials they preserve and restore, which doesn’t always happen.
You know, and there are, of course, not-for-profit archives that hold materials for which they don’t own the rights.
And that collaboration between rights owner and, you know, a non-profit archive is, you know, usually good, can be fraught, you know, that’s another part of this project as well.
I mean, we’re, Paramount gave the Library of Congress silent films back in the ’60s and ’70s because there was no concept of an archive, right?
And so, you know, that history plays into that, right?
When did we start actually caring about archives?
Maybe a little too late, right?
So those are complexities of the business too, where there wasn’t the funding, there wasn’t the interest in taking care of archives because the business wouldn’t take care of it.
That’s part of the equation as well.
Chris Lacinak: 56:55
From your perspective, what’s the bigger challenge, technology or finance or business?
Andrea Kalas: 57:02
I mean, I think no matter where you are, whether you’re in a studio or you’re in a not-for-profit archive, and I’ve worked in both, right?
You know, the phrase, “Everyone loves an archive until they have to pay for it,” applies, right?
So, you know, if you need the technology and you need to pay for the technology.
You need the vaults and you need to pay for the vaults.
You need the staff and you need to pay for the staff.
So figuring out how to make sure you’re making the best case for the archive is probably always the biggest challenge.
And when I talk to people in university classes, I say, “If you don’t like advocacy, you may want to pick another field.”
Right?
Because if you don’t feel like you’re, if you want to just sit somewhere and catalog something and everybody’s going to leave you alone, you know, that may be your perception of archiving.
But the reality is you constantly have to think, “Okay, let me, while I’m talking to this person, I’m going to collect this use case so that when I’m up against my finance person I can say, ‘This is why I’m doing this because this makes money or this helps our marketing or this does this.'”
You know, so you have to constantly be looking at, “All right, can we do it this way?
Can we do it this way?
Is this cheaper?
If we save some money here, can we spend it there?”
That always, always, always, that’s a big part of the archival project is making sure you’re speaking well about the importance of what you’re doing.
You know, I’m sure that my finance people are tired of hearing me saying, “Well, if we don’t have that asset, the revenue would be zero.”
Chris Lacinak: 58:51
Good argument.
Andrea Kalas: 58:52
I’m sure they’re sick of hearing me say that, right?
But that’s the, you know, no matter how you’re going to implement your archive strategy with technology or physical vaults or whatever it is, it’s about advocating for why you should do it.
Chris Lacinak: 59:09
That’s a perfect segue to the next question I have for you, which is kind of about the why.
You pointed out, you know, Paramount Pictures has an interest in preserving the Godfather because they want to monetize it 100 years from now too, right?
This is an asset that they want to continue to monetize, and that makes perfect sense.
But could you give us a fuller picture of the why?
Why is it important?
You know, and let’s just focus on the cinematic holdings of the organizations that are in the Digital Preservation Forum, as an example, and not that you speak on behalf of all of them.
But just in general, why is it important?
Other than the long-term monetization argument to preserve these holdings?
Andrea Kalas: 59:45
Look, I think anybody in any entertainment organization would recognize that there’s a cultural aspect to it too, that you do have within your holdings.
You know, I do think that movies are the greatest art form ever created.
You know, they have it all.
They have music, they have art, they have cinematography.
There’s, you know, I do think that there is an understanding that there’s a cultural responsibility even within a business, right?
That may be easier for a not-for-profit to talk about as part of their advocacy thing.
Within a business, that could be a little trickier, right?
Because they’re always just about the bottom line.
But I do think that there’s that part of it.
And I think that, you know, and one of the things I always sort of get called, you know, in on is historical aspects of the studio, right?
So that becomes relevant for marketing or for our corporate branding concepts or just generally talking about where Paramount Pictures comes from, where does it fit in the history of the entertainment industry?
You know, how these things happen.
And I think that part of it, and that’s something similar that you see across corporate archives generally, right?
Whether you work for Coca-Cola or Ford or, you know, there’s other, you know, big corporate archives that realize that that legacy of how they’ve built their business and the products or the things that they’ve created have enormous, you know, sort of relevance to their corporate brand and their corporate identity, but also are really interesting things to preserve among themselves, you know?
I remember seeing, you know, my colleague at Ford, you know, some of the incredible designs for cars that have been done by these amazing designers over the years.
And you know, fantastic.
Why would you throw that out?
It’s so important.
Yeah.
And I think people feel that way too within businesses to see that contribution that company made, that intervention in culture, that intervention in innovation is remembered.
So that’s another part of it.
Chris Lacinak: 62:02
Should we trust the entertainment industry to bear that burden or, you know, take that on to be the stewards of preserving these culturally important materials?
Andrea Kalas: 62:13
Yeah, no, I think it’s a good question.
You know, I think, you know, when I first started working at UCLA Film and TV Archive, you know, the studios were the baddies.
You know, they were the ones that let things not be taken care of.
I mean, UCLA Film and TV Archive was started because Paramount was getting rid of a lot of nitrate film because it was going to be illegal to keep it on the lot.
You know?
Chris Lacinak: 62:36
For those who don’t know, maybe we should tell people why that was.
You mentioned nitrate earlier.
Andrea Kalas: 62:41
k made, used very much before: 1950
Chris Lacinak: 63:02
That’s why it was not allowed on the lot.
Andrea Kalas: 63:05
It was a fire risk.
Right.
It was a fire risk.
So, and UCLA went and like literally picked up all the nitrate and took care of it.
So that’s how, you know, so that history of studios not caring is going to be with us forever.
Right.
I think, you know, we’ve definitely turned the tide on that and made it, you know, obviously there’s great restorations coming out of all the studios right now.
Every studio built has built vaults.
Every studio is now really engaged with digital preservation.
So I think there has definitely been a switch, major switch through those, from those days.
But you know, it’s a legacy that’s hard to beat.
Right.
It’s a legacy that is not proud.
As a result, you know, there’s a lot of silent films that are stored in the Santa Monica Bay, you know.
So that’s hard to get over.
Yeah.
And I think that’s the other reason for that.
Another sort of impetus of the Academy Digital Preservation Forum is let’s turn that on its head a little bit.
Chris Lacinak: 64:06
Yeah.
So the Academy clearly has taken on some responsibility by giving a home to the Digital Preservation Forum.
So is there a larger role for the Academy to play in the digital preservation or supporting or leading thought leadership of any sort?
Is the Forum the manifestation of that or is there something bigger, do you think?
Andrea Kalas: 64:27
I mean, the Academy is not a standards body, right?
So they’re not going to insist that the entertainment industry follow a particular model for digital preservation.
That’s just not their role.
They don’t see it as their role, you know.
And I can’t speak completely for the Academy, you know, I’m an Academy member that’s on the SciTech Council doing something I think is, you know, is important for film archives, right?
So and that’s great that the Academy lets its members do that, right?
They’re letting the members have a voice in some of the important issues of the day, whether it’s, you know, talking about diversity and inclusion.
Members are very important, you know, including that.
They’re giving them a voice that way.
Or whether it’s, you know, they had a big conference on AI and ML recently that crosses all the branches, giving them a voice.
So that’s what the Academy really does well, I think, is not insist on do it the Academy way, but say, we’ve got all these smart members.
They have a clue.
Let’s allow them to help by, you know, giving them that ability.
So that’s the role I think the Academy plays really well.
Chris Lacinak: 65:43
Who makes up the folks that are on the, I mean, the Forum itself, I think is open to, is it open to the public as far as who can engage on the Forum?
But there’s a working group or a group of contributors that are listed on the site under our team.
Who is the makeup of that group?
How did they, how did the group come to be formed?
And I guess just, I’m just trying to wonder, like, what are the skills, the expertise, the breadth of experience that is, that’s on the team there?
Andrea Kalas: 66:10
So mostly it’s what I talked about earlier, right?
When I decided that, you know, out of, so there’s a small working group that are SciTech Council members and others that are interested.
But you know, for that, that Curatorial Working Group I mentioned earlier, which are people from the different studios that are in roles similar to myself that meet regularly and talk about the issues of digital preservation and decide where we’re going and what things we want to tackle.
So that’s really what it is, is trying to collect up, you know, the people that are dealing, are on the front lines of this.
And have them be the people that are vetting ideas that would go to the Forum to what’s important to talk about, what should we do?
What video should we shoot next to put up there?
What’s critical about what we’re thinking about?
Chris Lacinak: 67:04
If you fast forwarded, you’re at a dinner with your colleagues on the Forum and you’re toasting to the successes of the Forum.
I guess, what’s your hopes, your dreams?
What have you accomplished at the point at which you say, yes, we’ve done it, you know, cheers.
What do you think the Forum can accomplish?
Andrea Kalas: 67:19
You know, I think, I still feel like we have a lot to do.
I feel like we’ve just started.
I feel like there’s, you know, there’s still a lot of, you know, I still, you know, I think people are still scratching their heads like, what is digital preservation?
I don’t get it.
You know, I don’t know if we’ve really answered this.
I feel like we still have loads of work to do.
I think there’s great stuff on the Forum for people to learn from, you know, but it’s complicated.
There’s not this one answer for digital preservation.
You just have to put this switch and you’re done.
Right.
And I think that’s, so a complex message is always a difficult one to get across.
Yeah.
Right.
And so, how we, you know, success for me would mean that digital asset management systems would have digital preservation baked into them no matter where they were.
They don’t right now.
Right.
That’d be great.
If you bought a digital asset management system off the shelf, you would always know you would have a protocol that would make sure your assets were preserved.
That would be success.
That would be one version of success for me.
Right.
Or that, you know, or everybody that’s ever making a moving image has a plan for how they’re going to make sure that those assets are replicated, that they are validated annually, that you can find them easily.
You know, that if everybody had a plan to do that, that would look like success.
I think we still have a long way to go.
Chris Lacinak: 68:44
Yeah.
And digital preservation, I think, is deceitful in the sense that it is so simple in many ways and so complicated in others.
Right.
I mean, the basics, the fundamentals on the technological side are pretty straightforward.
I think there’s some strong basic business arguments for why it makes sense.
You laid out many of those today.
There’s cultural reasons, but it does get really complex really quickly when you dive into the details.
So, yeah.
How important is it that the major players in, let’s say, the studios, the holders of cinematic collections, do essentially the same thing with regard to their outputs?
Obviously, they’re going to have different workflows.
There’s going to be different little nitty gritty details that are going to be different.
That doesn’t matter much.
But file format choices, maybe digitization technology.
How important is it that that’s similar or not?
Andrea Kalas: 69:42
I think the way that if people can do things in a more similar way, what’s helpful about that is it’s not as confusing.
For example, one of the things we’re working on right now is this concept of what’s called the picture preservation package.
Right?
So, at the end of a film, when you’re working with a post house, they output what would be called a digital intermediate.
Well, now there’s all sorts of different names for these different versions of digital intermediates.
NAMS, GAMS, consolidated archives, all these different kinds of things.
And so, both post production people who are finishing the film as well as the facilities where they’re being done, it’s like, “Oh, God.
Why can’t they decide on one thing?
There are all these different versions, and I have to make this for this studio and that for this studio and that.”
So, that’s confusing, and it could mean more mistakes are made or it’s not done well.
So, if there’s a similar process, I think that helps everybody.
Everybody can just point to it and go, “That’s what I want.
Please do that.”
And if we can also make that easy to be created by working with some of the software vendors that create the DIs, then it’s allowing people to make preservation assets a little easier and there’s more potential for them to be made.
So, I think that it’s not a standard.
It’s not insisting anything.
It’s just like, “Here’s something.
If we could all agree on this, make it up.”
Chris Lacinak: 71:19
You’ve just touched on something there that I think is interesting.
From my perspective, I work with lots of media and entertainment folks, but it’s not what I do all day, every day.
I work with a lot of different verticals.
So, what I see is that, I mean, you talked about vendors and that just made me think.
My observation has been that there is a closer collaboration between archives, digital assets, holders of content and digital assets and vendors in the media and entertainment world than there is other places.
I don’t know if you can comment on whether that’s true or not.
You’ve been in a variety of verticals too, but I guess I wonder, how do you see that relationship fostering the ultimate goal of digital preservation?
Chris Lacinak: 72:04
It’s like anything else within a business.
Sometimes you want to do it internally.
Sometimes you want to outsource it.
People outsource all sorts of different things.
Some people outsource their entire media supply chain to a company.
When they’re finished with it, they hand it over to somebody to make sure it gets out to all the different final clients that it needs to get out to.
Conform all the languages, they do all that work.
Other people don’t.
Other people do it in-house.
Certainly within feature film and television production, the post house is almost always an outside vendor.
They might have colorists that the director prefers.
It’s very important to maintain that relationship.
That integration between different vendors.
There’s certain things that it would be difficult for us to insource too.
People that do localization, they have linguists all over the world and things like that.
There’s some work that’s impossible for everybody to take in-house.
That’s constantly being looked at and revised.
Technology is a big part of that.
If you can do it simpler and there’s technology that makes things not as complicated as it used to be, it’s constantly going back and forth.
There’s also outsourcing of archives too.
People will have a vendor that will do digital preservation for them.
That’s another possibility.
Yeah, it’s part of the landscape generally, I would say.
Chris Lacinak: 73:57
They are an important stakeholder at the table in the conversation, it seems.
Andrea Kalas: 74:02
They are.
Yeah.
Chris Lacinak: 74:04
When I look at the list of folks that are on the Curatorial Working Group and you have folks listed as additional contributors, it seems like you’ve got …
We’ve touched on finance.
It seems like you’ve got people that are executives.
You’ve got people that are technology-centric.
I think it’s fair to say some vendors, I don’t know if that’s an accurate assessment or not, is that folks that are-
Andrea Kalas: 74:23
Yeah, there’s not as many vendors as there could be.
That’s a discussion too.
It’s kind of tricky with the Academy because they don’t want to be shown as supporting one business over another.
That’s a tricky part.
If we had an event, which we’re talking about doing right now, and that would be definitely one topic that I would love to have is more people from post houses really having …
Because there’s really smart, great people with all sorts of great innovations going on all the time.
Yeah.
They’re part of the conversation, absolutely.
Chris Lacinak: 75:01
Switching a little bit, I guess I wonder, should people think about this being a US-centric thing or is this a global endeavor, the Forum that is?
Andrea Kalas: 75:10
I think because it’s the academy, it’s Los Angeles, because it’s traditionally tied to the studios, it’s definitely been US in its concept now.
Although we did have …
There are other members of the Academy that are now coming in.
On the group right now is somebody from India, somebody from the Netherlands.
That’s a bias, but it’s not exclusive.
Trying to get a wider perspective on it is absolutely essential.
Yeah, I would love to see …
That’s our biggest challenge right now is how do we get more involvement.
Right?
How do we …
We can’t invite everybody into a curatorial working group.
Right.
We want to focus them on the Forum, but how do we get people interested and engaged and active in that?
That’s what we set it up for, right?
So it could be wider.
It could be a broader group.
That’s partly why I’m doing this podcast, is to get the word out about it, because that’s why we want people.
We want everybody’s input.
We want to hear what we’re doing right, what we’re doing wrong.
What can we do better?
How can we …
What other issues are we not thinking about?
So we want that feedback.
Chris Lacinak: 76:32
Who should pay attention to the Forum?
It sounds like it’s not just folks with cinematic holdings, not just people in the US.
Who do you think that the content and the subject matter is relevant for?
Andrea Kalas: 76:44
I would love to see ultimately more people that own the purse strings for archives be much more aware of archives.
I would love to have the forum reach even up to that level.
That would be my ideal.
But I think, obviously, filmmakers, archivists are an obvious one.
We mentioned vendors like post-production houses.
I’d love to see them much more engaged with it.
Technologists, people who are building things, right?
It would be great if a cloud company came to us and said, “Hey, we’re thinking about how to do digital preservation in the cloud.
What do you think?”
That hasn’t happened yet.
I’d love to see that happen.
That’s where I think as broad a possible audience of stakeholders would be amazing.
Chris Lacinak: 77:40
Well it’s come to the time where I ask the final question that I ask all the guests on the DAM Right Podcast, which is, what’s the last song that you added to your favorites playlist?
Andrea Kalas: 77:54
Probably something from ’70s funk.
That’s really where I go all the time, or disco.
Chris Lacinak: 78:02
Give us one of your favorites.
We’ve got a podcast playlist that is assembles as all of these.
Just give us one of your favorites.
Andrea Kalas: 78:08
All right.
Let’s see.
Gloria Gaynor, “I Will Survive.”
Chris Lacinak: 78:14
All right.
Love it.
That’s a very suitable song.
Love that.
That should be the theme song.
Andrea Kalas: 78:19
In the realm of preservation, right?
Chris Lacinak: 78:21
I love that.
Well, Andrea, thank you so much for taking the time to talk with us today.
It’s been fascinating.
I could talk for two more hours.
I want to just dive into just your career path.
That’s fascinating.
That’s so cool.
I love it that you joined me today.
I really appreciate all the insights and just everything you brought to the table.
Thank you.
Andrea Kalas: 78:42
It was a pleasure talking to you, Chris.
Thanks for your time.
Chris Lacinak: 78:44
Do you have feedback or requests for the DAM Right Podcast?
Hit me up and let me know at [email protected].
Looking for amazing and free resources to help you on your DAM journey?
Let the best DAM consultants in the business help you out.
Visit weareavp.com/free-resources.
Stay up to date with the latest and greatest from me and the DAM Right Podcast by following me on LinkedIn at linkedin.com/in/clacinak.
The Digital Transformation of Holocaust Testimony Archives
25 April 2024
Preserving and accessing Holocaust testimonies is crucial in today’s world. As misinformation and historical revisionism continue to increase, archives play an even more essential role. Therefore, Yale’s Fortunoff Video Archive for Holocaust Testimonies serves as a beacon, reshaping how we engage with survivors’ stories. This blog covers the archive’s evolution, challenges, and significance, highlighting the vital efforts made to safeguard these memories for future generations.
The Origins of the Fortunoff Video Archive
The Fortunoff Video Archive began in New Haven in 1979 as a grassroots initiative. Survivors and their families founded it to record and preserve Holocaust oral histories. This effort aimed to ensure that survivors’ voices would never be forgotten.
Initially, the archive operated as a nonprofit, using analog video equipment to record testimonies. Survivors often participated as both interviewers and interviewees, thereby creating an intimate setting. As the project gained support and funding, it eventually became affiliated with Yale University in 1981.
Transitioning to the Digital Age
Digital technology sparked a major transformation for the archive. Between 2010 and 2015, it transitioned from analog to digital formats, digitizing over 10,000 hours of testimony. This process required meticulous planning and skilled technicians to maintain the recordings’ original quality.
Notably, Frank Clifford, a dedicated video engineer, played a pivotal role in this transition. His expertise ensured that the digitization maintained the authenticity of the archive’s materials, allowing the archive to move seamlessly into the digital age.
Enhancing Accessibility Through Technology
Moreover, the Fortunoff Archive embraced technology to improve accessibility. The development of the Aviary platform marked a key milestone, enabling users to search and access testimonies online. This platform uses advanced indexing systems, which help users navigate the extensive collection efficiently.
In addition to video testimonies, the archive has also developed transcripts and indexes for research purposes. Although these indexes were originally handwritten, they have since been digitized, synchronizing with the video content and aiding researchers in locating specific topics within testimonies.
Ethical Considerations in Archival Practices
Importantly, the archive operates with strong ethical guidelines, always prioritizing survivors’ well-being. Each testimony includes a release form, giving survivors control over their narratives. This ethical focus extends to how access is managed, ensuring the archive remains sensitive to the subject matter.
Furthermore, over 200 affiliated institutions worldwide now offer access, enabling researchers to engage with testimonies while maintaining survivor confidentiality. This approach reflects the archive’s deep respect for the individuals whose stories are being preserved.
Engaging the Public: Outreach and Education
In addition to preservation, the Fortunoff Archive actively engages the public through various initiatives. For instance, the podcast “Those Who Were There” shares testimonies in an engaging audio format, making survivor stories more accessible to a broader audience.
The archive also offers educational programs, film series, and fellowships. As a result, these initiatives promote a deeper understanding of the Holocaust, encouraging empathy and awareness among future generations.
Challenges in the Digital Landscape
While the digital transformation has increased accessibility, it has also brought challenges. Misinformation and Holocaust denial, for example, threaten historical narratives. Consequently, as digital manipulation becomes more prevalent, verifying sources has become more important than ever.
The archive also faces challenges related to copyright and ownership, ensuring survivor rights are protected. Therefore, balancing accessibility with ethical responsibility remains a central concern.
The Future of Holocaust Testimony Archives
Looking ahead, the future of the Fortunoff Archive lies in collaboration and innovation. As technology continues to advance, integrating Holocaust testimony collections across platforms becomes possible. Consequently, efforts to create a centralized platform will enhance research and collaboration among institutions.
Furthermore, as fewer witnesses remain, preserving these testimonies becomes even more urgent. The Fortunoff Archive remains dedicated to ensuring survivors’ voices are heard in our collective memory.
Conclusion: The Importance of Remembering
In conclusion, the Fortunoff Video Archive’s work is vital in preserving survivors’ stories from one of history’s darkest times. By combining technology, ethical practices, and public engagement, the archive honors these memories. As we look ahead, it is our responsibility to carry these stories with us, ensuring the past’s lessons continue to guide our present and future actions.
Transcript
Chris Lacinak: 00:00
Hello, thanks so much for joining me on the DAM Right Podcast.
To set up our guest today, I want to first set the stage with two important items.
I founded AVP back in: 2006
Actually April 21st was our 18th year anniversary, so happy birthday to AVP.
Anyhow over the past 18 years, I’ve had the privilege of working across a number of verticals.
Anyone who has worked in a number of places within their career will know that one of the big and important parts of onboarding and becoming a productive part of a new company is learning and using the terminology.
Each organization has its unique terms and the distinct way that they use those terms.
So you’ll understand when I say that the thing that has differed the most in working across verticals has been the terminology.
Our corporate clients talk about DAM, our libraries and archives clients talk about digital preservation, our government clients talk about digital collection management, and so on.
In truth, there is a great deal of overlap in the skills and expertise necessary to effectively tackle any of these domains.
Of course, there is nuance that is important and distinct, which is mostly about understanding purpose, mission, context, and history.
This is akin to learning the terminology of a given workplace and coming to understand the things that make each workplace unique.
Like anywhere, the use of a terminology is a signal to people about which tribe you are part of.
Just as words have meaning, how you use those words has meaning.
For years, this reality has caused a great deal of consternation for us at AVP.
Why?
Because we have always worked with an array of customers, we have always had to make sure to be careful and precise in our use of terminology.
With an individual customer, this is easy.
With a website, this is very difficult.
On a website, you have to choose the terms that will resonate with your target audience and have them know that when they land on their page, they are with their people.
We didn’t want people who talk about DAM to see us talking about collection management and vice versa, thinking that they were not with their people.
But in wanting to avoid offending anyone, we failed to talk effectively to everyone.
In: 2021
Since then, I’ve been relieved to find that 1) we have offended very few of them, and 2) these verticals have also started to embrace the term digital asset management themselves.
Even more, these verticals have started to embrace technologies that use the DAM label.
And conversely, technologies that use the DAM label have started to represent the interests and needs of people who consider themselves to practice digital collection management and digital preservation.
I say all this as a backdrop because the focus of today’s episode is on an archive of video Holocaust testimonies.
It almost feels wrong to refer to these testimonies as “digital assets.”
But even though my guest does not use any technology that refers to itself as a DAM, the practices and skills that are used are digital asset management practices and skills.
A common refrain for digital assets is that they are not digital assets until you have the rights and the metadata to be able to find them, use them, and derive value from them.
Historically, in the distinctions that have existed between the use of the terms digital asset management and digital collection management, one of them is the definition of value.
In DAM conferences 20 years ago, if you talked about digital assets and value, you could be certain that 90% or more of the people in the room were thinking dollar signs.
And if you were at an archive conference and you talked about digital collection management and value, you could be certain that 90% or more of the people in the room were thinking of cultural and historical value.
And while I think this is becoming less true over time, it feels important to say that in this podcast episode, and in the podcast in general, when we talk about digital assets and their value, that we mean any and all of the above.
It is very true to say that a file without rights and metadata has no value of any sort financially, culturally, historically, or otherwise.
If you cannot find it, if you cannot use it, it has no value.
So in this episode, I want to ensure our listeners that there was a great deal of meaning and relevancy in calling these Holocaust testimonies digital assets.
They are truly assets that have a great deal of value in the most holistic and meaningful of ways.
Having said that, and with the Holocaust Remembrance Day coming up on May 6th, I am privileged to have the Director of Yale’s Fortunoff Video Archive for Holocaust Testimony, Stephen Naron with me today.
Prior to becoming the Director, Stephen was an employee at the Fortunoff Archive where he worked extensively on this collection of materials and helped guide it into the digital age.
Since becoming the Director of the Fortunoff Archive, Stephen has been prolific and innovative in his work to make these testimonies available to the public and to proactively use the materials in the archive to create compelling experiences for people to discover and engage with these testimonies.
This has included collaborating on the development of a software platform, launching a podcast, releasing an album, running a fellowship program, and running both a speaker and a film series.
And that’s not even all of it.
I’m so thrilled to have Stephen Naron on the DAM Right Podcast with me today and to introduce him to the DAM Right audience.
Remember, DAM Right, because it’s too important to get wrong.
Stephen Naron, welcome to the DAM Right Podcast.
I’m super excited to have you today.
Very glad to be talking with you about all kinds of topics around DAM and this amazing collection and archive that you’re the Director of.
Thank you for joining me.
Stephen Naron: 05:40
Oh, it’s a pleasure to be here, Chris.
Thanks.
Chris Lacinak: 05:42
I wonder if we could start with you just giving us a background about your background, your history and kind of how you came to be where you are today.
Stephen Naron: 05:51
imonies, on and off now since: 2003
So it really was my first professional job as a librarian and archivist.
But obviously, I’ve always had a deep interest in Jewish history and Jewish culture and Jewish languages.
And I studied abroad, learned Hebrew and Yiddish and German.
And while I was in Germany as a graduate student, I was lucky enough to get a position in an archive at the Centrum Judaicum as a student worker.
And it was the [speaking in foreign language] and this is a sort of general archive for all of the Jewish communities in Germany.
And I worked with that collection for over a year as a student worker.
And that’s when I really was bitten with this sort of bug, this interest in archives in general.
And so that’s when I decided to sort of turn towards the field of archives and libraries.
And when I got my degree, I focused on archives in UT and Austin, which was a great program.
I learned a lot.
And then right out of library school, I found the position at the Fortunoff Video Archive.
And so it really was the first professional experience I had.
And I just loved working with this collection.
It’s a collection that’s exclusively audio visual testimonies of Holocaust survivors and witnesses of the Holocaust.
And yeah, so that’s a little bit about my academic background and how I became interested in working in particular with audio visual collections.
Chris Lacinak: 07:45
Wow.
So you’ve been at the archive for quite a while now.
When was that that you started there?
Stephen Naron: 07:51
In: 2003
And then I moved to Europe with my wife and we were in Sweden.
f years and then came back in: 2015
Fortunoff Video Archive from: 1984
And so I had a wonderful opportunity to mentor, to have her as a mentor and learn really from the individuals who helped build the collection over the last 45 years.
Chris Lacinak: 08:46
And has the archive always been under the auspices of Yale University or did it start independent from Yale?
Stephen Naron: 08:53
Well, that’s one of the most interesting things about this collection is that it actually started in New Haven as a grassroots effort of volunteers and children of survivors, survivors, fellow travelers who formed a nonprofit organization in New Haven to record testimonies of Holocaust survivors and witnesses.
o it didn’t come, that was in: 1979
first tapings were in May of: 1979
And it really was very much an effort from the ground up.
Survivors were in the leadership of the organization, the nonprofit, president of the nonprofit was a man named William Rosenberg, who was a survivor from Częstochowa, Poland.
Survivors would hold meetings in their homes to organize the tapings.
They’d fund the rental of what was at the time quite expensive video equipment to do this professional broadcast, professional standard recordings.
And of course, survivors served as interviewers and as interviewees.
So they were on both sides of the camera.
And so that’s in the early days, ’79 starts.
survivors who was recorded in: 1979
And Renee happened to be married to a professor at Yale, Geoffrey Hartman, who was a professor of comparative literature.
And so Geoffrey became involved in this sort of local project, community project, very early on.
And he, as an academic, knew how to write grants.
And so he wrote a number of successful grants to help increase the funding of the project.
And he was then really responsible for bringing the collection and giving it a permanent home at Yale.
o it was deposited at Yale in: 1981
And at that time, there were about 183 testimonies that had been recorded by the Video Archive’s predecessor organization.
This organization was called the Holocaust Survivors Film Project.
So this project then became the Video Archive for Holocaust Testimonies.
And there were about 182 testimonies at the time, and it’s now grown to over 4,300 testimonies.
It’s 10,000, more than 10,000 hours of recorded material.
It was recorded in North America, South America, across Europe, in Israel, in over 20 different languages, in over a dozen different countries, with the help of what we call affiliated projects, which are independent projects that form a collaborative agreement with the Fortunoff Video Archive.
And so it has just grown exponentially.
And ever since ’82, we’ve been serving the research community.
They come to Yale, use the collection there, hundreds of researchers every year.
And then in about: 2016
And so these access sites are all over the world.
There are over 200 of them.
And usually institutions of higher learning or research institutes.
So the collection has been, not only has it, did it grow from a small grassroots effort into a sort of a global documentation project, but it’s now readily accessible all over the world.
Chris Lacinak: 12:49
You’ve hinted at several things that I just want to kind of put on the table so listeners understand, but the Fortunoff Video Archive for Holocaust Testimonies is all video recordings.
Is that right?
Stephen Naron: 13:01
Yeah, right.
It’s exclusively video recordings.
And in fact, it was this HSFP, the Holocaust Survivors Film Project, was the first project of its kind to begin recording video interviews with survivors on any sort of extended basis.
So we really are the first sustained project of its kind.
And by sustained, I mean really sustained.
our most recent interview in: 2023
So we’re talking about over 40, almost 45 years of documentation.
And so that provides quite a unique longitudinal perspective of this whole genre of Holocaust testimony.
There’ve been lots of many, there’ve been many other projects that followed in our wake.
But most of them rise and fall fairly quickly.
This is a project that’s really withstood the sort of test of time.
rs, who were recording in the: 1980
So when we get a call from a survivor who wants to give testimony and who hasn’t given testimony before, we pull in some of the most experienced interviewers there are who have done this type of work.
Chris Lacinak: 14:29
You mentioned that these were originally recorded, many of them, you’re still recording them, so you’re not recording them on analog videotape today.
But originally they were recorded on what was considered broadcast quality analog videotape.
You talked about there being a digitization process of everything in your collection, I believe at some point along the way.
Could you just tell us about like, what are some of the other, I assume there’s transcripts and other aspects.
Can you tell us a little bit about just what does the collection look like and kind of what are some of the salient steps that you’ve taken to make it usable, preservable, accessible?
Stephen Naron: 15:07
There is a story there.
Because this archive has had such a long history, it’s gone through, and it’s from the very beginning been an archive that is, let’s say, I don’t want to say groundbreaking, but certainly forward thinking in its use of technology from the very beginning.
Just the embrace of broadcast video alone was sort of at the time a revolutionary step.
But beyond that, the Fortunoff Video Archive has always been sort of a step ahead, at least in the larger library system at Yale, in thinking about how to make the collection accessible, embracing digital tools, cataloging through Arlen and other sort of central online searchable databases.
We were one of the first collections on campus, if not the first collection on campus, to have its own website.
So we’ve always embraced technology, at least for the benefits that it can bring in terms of making this collection more accessible and more available to the research community.
But as far as what other content or what other layers of information that we’ve had to sort of transform from an analog to a digital world, yeah, we’ve had the videos themselves.
And that took over five years, where we had an incredible video engineer named Frank Clifford, who used to work at Yale Broadcast, who then came over to the Fortunoff Video Archive and by hand, using SAMMA Solos and a fleet of U-Matic and Betacam decks, digitized all 10,000+ hours of video in real time, day after day after day for years.
Sadly, he passed away.
But really, he did just an incredible work.
And as you know, as someone who’s worked hands-on with analog legacy video, he kept those machines running by all means necessary.
h shedding tape that was from: 1979
And so, that’s just one step, right?
But then we have all these analog indexes that were handwritten, handwritten notes that describe the content of each interview that then became typed indexes.
And those indexes were in WordPerfect and various versions of Word and OpenOffice.
And so, we have this whole other effort of standardizing and migrating the indexes from one format to another.
We eventually moved everything into OHMS.
So now, all those indexes have been OHMSed, and we’ve connected, of course, the OHMS indexes with the video.
And so, that was a huge effort.
Chris Lacinak: 18:21
Let me stop you just for a second, because I think there’s probably many people that don’t know what indexes are, or at least how you define them, and OHMS.
So maybe let’s just drill down a little bit on that.
What’s an index?
What’s it look like?
How does it work?
And what is OHMS?
Stephen Naron: 18:36
Okay.
So, the indexes are a little idiosyncratic for us, right?
So, we call them indexes.
We used to call them finding aids, which is a lot more in tune with the kind of archival world.
But they weren’t really finding aids per se, either, although they did allow us to find things.
What they were are detailed notes in the first person in English, regardless of what the language of the testimony is.
So, first person notes written by students who had the native language of the testimony they were watching, and they’re very, very summarized.
So, they read kind of like transcripts, but they aren’t transcripts.
They’re not word for word.
The goal was to capture the most salient details of the testimony in as terse a form as possible.
And every five minutes, the student would put a time code from the video, a visible time code, so that researchers could then use these indexes or notes or finding aids to find specific speech events in the testimony.
This was long before you had SRT and WebVTT kind of transcripts, right?
You’d use this paper.
So, they’d get this paper indexed.
They’d take it with them.
They’d have the video, VHS use copy, sitting in manuscripts and archives in Sterling Memorial Library, and they’d be looking through the notes and trying to find the section of the testimony that was most relevant for their research.
And so, those notes exist, those indexes, those notes, those finding aids, they exist in a number of different forms.
And even more confounding, the notes, the indexes were created from the use copies, and the use copies had visible time code, and that visible time code did not refer, was not the same time code as the original master tapes, because the VHS use copies, of course, don’t start and stop at the same time as the master tapes.
So, there was this discrepancy between the time code on the notes and the time code on the master tapes, so we couldn’t use the indexes properly with the digital master videos.
So, that’s why we sort of came up, and there was no like programmatic way to just mathematically transform the index timing to the master tape timing.
So, that’s when we found OHMS, and we saw that OHMS was just a sort of ideal system where you could synchronize, and OHMS stands for Oral History Metadata Synchronizer, and you could use OHMS, it was a free tool, it is a free tool that you can use to synchronize text-based data, so indexes, finding aids, transcripts with the digital audio or video.
And so, we did that with the entire collection, which also took us years, but now we have all the indexes are searchable and full-text searches in Aviary, which allows researchers enormous amount of flexibility in terms of locating specific topics and events within a testimony or across all the testimonies.
Chris Lacinak: 21:40
And you created indexes which were not transcripts, was that because of the amount of time it took, was that because that’s what current best practice was?
Why did you take that route instead of transcripts at the time?
Stephen Naron: 21:53
That’s also a really good question.
Well, actually, there is a practical side, it simply was too time-consuming and expensive to create full transcripts, and this is a collection that really grew very slowly and has had limited resources its entire existence, so we had to be cautious about where we sort of put our resources.
And so, these indexes seemed like the quickest, most cost-effective way to gain intellectual access to the collection.
And the archivists used these indexes then to create catalog records, regular old MARC catalog records, almost like every testimony was cataloged, almost like a book.
And you could then search across those catalog records.
But beyond the practical side, there was also an ethical and I think intellectual reason not to go the path of transcripts.
One was that no transcript, no textual transcript can truly capture the richness of an audio-visual document.
You cannot capture gestures, you cannot capture tone, you cannot capture pauses that are very meaningful in a recording like a video testimony of a survivor, the look in the eyes.
I mean, these are things that cannot adequately be captured in a transcript.
And so, the thought was if you can’t make an accurate transcript, we have to really push the viewer to watch the recording.
And again, that’s also part of the ethos of the archive is that we want you to watch.
We want you to witness the witness, right?
We want you to be present, entirely present.
And if you provide transcripts to researchers, as we all know, the researchers will go straight to the transcripts and use the transcripts and might not even watch the video.
And that’s big, you know, some researchers are lazy like that.
But we felt that that was an ethically unsound use of video testimony.
And so, we really want to, we sort of pressure, let’s say, or coerce the researcher to watch the video and to watch the video in its entirety.
And I think that’s an obligation.
There’s an ethical obligation there that needs to be followed.
Chris Lacinak: 24:28
Yeah, that’s really interesting.
So, you didn’t want to mediate, it sounds like, you didn’t want there to be a mediation between the person that was watching or using these materials and the original testimony.
That’s super interesting.
It makes a lot of sense.
Stephen Naron: 24:40
Well, I mean, it also, it does make sense because, I mean, think about it.
If you read a transcript and it’s read by the, and it’s spoken by the survivor with an ironic tone of voice, how are you supposed to understand that there’s irony or sarcasm in a transcript?
You have to listen and watch in order to truly grasp what’s happening.
Otherwise, researchers will quite simply make mistakes.
They will misquote and misinterpret.
Chris Lacinak: 25:09
So I sidetracked you there.
You were kind of on a path talking about the various elements that you have in the archive.
You were talking about indexes and ohms when I stopped you.
And were there other things that you wanted to talk about there?
Stephen Naron: 25:22
Well, there are a couple of other things that are interesting and we’re still trying to figure out how to integrate them.
One is we conducted something called a pre-interview.
All of the testimony, so the process that we follow when we record testimonies is that there’s contact with the survivor several weeks or a week before the interview and the interviewers who are going to be at the session call, one of them at least, calls the witness and informs them about how it’s going to work, that it’s a very open-ended interview process, that they’re going to introduce themselves at the beginning and they’re going to tell us their, you know, start from their earliest childhood memories all the way up to the present, there aren’t set questions.
But they then also ask them a series of questions, mostly biographical questions.
Where were you born?
When were you born?
What did your parents do?
Did you have any siblings?
And so they gather all this information prior to the actual interview so that they can then go back to the library and do research about this person’s life.
So the town they’re from, learning about the town they’re from, learning about the camps and the ghettos that they might have been in, you know, really diving into this person’s life so that when they show up in the actual recording, the interviewers are already well informed about this person’s life.
They know the names of the siblings and the parents and what they did and they don’t have to ask these questions because they know it.
And then they can just serve as sort of guides or assist the witness as they really tell their life story in as open a manner as possible.
So those pre-interview forms are really interesting.
Also because the interview, once they get into the recording studio, there’s a lot of unknowns.
So sometimes the information that’s on the pre-interview doesn’t make it into the interview because the interview has a kind of life of its own.
But we need to find a way to make the data in those pre-interview forms more accessible to the researchers because there’s some interesting information there.
And then the other piece is we’re creating transcripts now.
So as I mentioned, those indexes, those finding aids, they’re always in English no matter what the original language is, which can be really frustrating for researchers who know these languages and then have to search in English, let’s say, to find information in a Slovak testimony or a Hebrew testimony or a Yiddish testimony.
So we’re now in the process of transcribing the entire collection in the original languages so that native speakers and researchers can search across testimonies in their language, which is in a way a compromise and a move away from what I said earlier about, you know, we want to, if we provide transcripts, then the risk is that people will just use the transcripts and not to watch the video.
But we felt this was a necessary step in this day and age to provide further intellectual access.
Chris Lacinak: 28:39
Well, it also seems that there’s been a major technological leap, whereas today I know the way that you provide access to transcripts is synchronized with the testimony.
So I mean, that’s a very different experience than maybe 15 years ago where someone would have just gotten that transcript and may have never watched the testimony, right?
That seems like that’s a very different experience and stays true to what you said about why it was important not to do that at the time.
Stephen Naron: 29:05
Yeah, absolutely.
And also think about, we’ve also been approaching transcription with another, you know, another motivation.
And that is that obviously people who are hearing impaired can’t take advantage of an audio visual testimony in the same way that a hearing person is.
So to be able to provide the transcript and subtitles for testimonies is also really valuable.
The other thing is even many of these testimonies can be extremely difficult to understand because of the survivors often are speaking in a language that isn’t their native tongue.
And so there’s a lot of heavily accented testimonies.
And so having transcripts and subtitles, transcripts as subtitles can be really valuable for everyone.
Chris Lacinak: 29:56
Speaking of the technological leap, some of the things you were talking about, right?
Writing indexes down on paper, pre-digitization was videotaped.
When did you do the digitization work again?
What year or years?
Stephen Naron: 30:07
So I would say: 2010
And we still, you know, even when we launched Aviary, the vast majority of the digital, the digitization work had been done by the time we were able to launch Aviary and make the testimonies accessible at access sites.
Chris Lacinak: 30:28
Two points about that.
One is it sounds so archaic this day and age, right?
Writing indexes down on paper.
And I believe there’s probably many modern practitioners that think that that sounds absurd.
But two points, one, that wasn’t that long ago and that was not unstandard.
That was pretty typical of what you’d find in a lot of people that were managing collections, especially of analog materials.
Two, just as an insight into, you know, your one archive out of many archives in the world and just to think about how many people haven’t done what you’ve done, which is the digitization work, the transcription work, the, you know, you’ve, as you said, you’ve embraced technology and that’s not to put anybody down that hasn’t.
It’s just to kind of get a moment, a glimpse into how many things that are out in the world that were created not that long ago and for decades prior that still may be not accessible in some way.
Stephen Naron: 31:33
Yeah.
And I mean, also like if you think about a traditional, you know, many traditional oral history, oral history projects, they would often record on tape or video and then create the transcript and then hand the transcript to the interviewee who would then, you know, sign that this transcript is an accurate depiction of my statement, right?
And then they’d actually get rid of the original tapes because the transcript then becomes kind of the document.
So yeah, that’s, we’re very different.
We’ve approached this very differently than a lot of oral history projects.
And yeah, absolutely, we’re really lucky that this collection, as I said, it, you know, it’s still a very small in terms of human resources who work with this collection, but, you know, we’ve been lucky to have the longevity that we have and to have the support from Yale University Library that really allows us to focus just exclusively on this collection, right?
So from the beginning, there has been this laser focus on making this as intellectually accessible and usable and standard, right?
So we’ve used, you know, standard library and archival practice to make this collection accessible using, you know, terminologies and taxonomies like Library of Congress subject headings and things like that, that make it very easy to share our metadata with others to search across collections.
And so yeah, I think we’ve been very lucky to be a part of a research library from the very beginning, which helped us to go down that path of description and description upon description upon description.
Chris Lacinak: 33:22
Thanks for listening to the DAM Right podcast.
If you have ideas on topics you want to hear about, people you’d like to hear interviewed or events that you’d like to see covered, drop us a line at [email protected] and let us know.
We would love your feedback.
Speaking of feedback, please give us a rating on your platform of choice.
And while you’re at it, make sure that you don’t miss an episode by following or subscribing.
You can also stay up to date with me and the DAM Right podcast by following me on LinkedIn at linkedin.com/in/clacinak.
And finally, go and find some really amazing and free resources from the best DAM consultants in the business at weareavp.com/free-resources.
You’ll find things like our DAM Strategy Canvas, DAM Health Scorecard, and the Get Your DAM Budget slide deck template.
Each resource has a free accompanying guide to help you put it to use.
So go and get them now.
And I guess you also have the benefit, although the archive is large in absolute terms and relative terms, it’s fairly small.
So that gives you an advantage to be able to really dive deep and do a lot of great work around, you know, compared to an archive that might have hundreds of thousands of recordings or millions of recordings.
Stephen Naron: 34:35
Yes, for sure.
Chris Lacinak: 34:37
The Fortunoff Video Archive for Holocaust Testimonies is not the only archive of Holocaust testimonies in the country or in the world.
And each of those have had to make decisions about where, when, how to give access.
And my understanding is that different decisions have been made about how to provide access to testimonies.
I wonder if you could just give us a sense of the, what’s the landscape?
You know, are there a few or are there dozens of archives of Holocaust testimonies?
And help us understand what some of the, and I’m not trying to, you know, I’m not trying to say that anybody’s right or wrong or anything like that, but just understand some of the considerations about that these archives have had to navigate in thinking about how to provide access to Holocaust testimonies.
Stephen Naron: 35:29
There are many, many collections all over the world.
after us, after we started in: 1979
And they do have indeed very different approaches to making the collections accessible.
, we have to remember that in: 1979
sn’t really established until: 1993
And prior to that, there weren’t a lot of other organizations doing this work in the United States or in North America.
But the US Holocaust Memorial Museum is a national institution.
It’s a government-funded institution.
And so the materials that they create, the testimonies that they’ve created and collected over the years, they have been given a very broad, sort of broad permission to make those as accessible as possible.
And I think that’s in part because they see their mission as a sort of general, you know, educational effort, right?
The general public to educate the American people about the history of the Holocaust.
In order to do that best, they have to make their sources as accessible as possible.
That includes testimony.
So their testimonies, of which they have thousands, are all digitized and accessible in their collection search online.
So there really are no barriers at all to the average citizen researcher who wants to go in and watch as much unedited testimony as he or she desires.
So that’s a very open model.
And I think it has a lot of, there’s a lot of benefits to that.
I do sometimes wonder how much of the general public is really interested in watching an unedited 10-hour testimony of a Holocaust survivor, how much of that they really, how many really do that.
But for the average, for the research community, certainly it’s an enormous advantage.
There are other institutions that on a national level, like Yad Vashem in Israel, Yad Vashem has an enormous collection of testimonies, both that they’ve created themselves and that they’ve collected over the years.
Some of those, many of those are available online, but many, I would say the vast majority, are only available to researchers who are then on site.
So they have a slightly more restrictive approach.
But their aim has been to collect as much of the source material as possible, either in original form or as digital copies.
So they’re a little bit more restrictive in a sense.
And then you have another major collection, the USC Shoah Foundation, which was started by Steven Spielberg after the release of Schindler’s List in ’94.
And he and his organization, the organization that grew out of this initial impulse, collected something like 50,000 testimonies of survivors, but in a very short period of time, so I think about less than 10 years.
And they’re now at USC, but they weren’t at USC originally.
They were on the Universal Studios backlot, I think.
And so they had a very different approach to this work, almost outside of the traditional world of academia and libraries.
And for a long time, their collection was only accessible through, and it still is for the most part, only accessible through subscription, a subscription model.
And so they became, they have this enormous, incredible collection, but it’s only accessible to at universities and research centers that have the resources to pay for that subscription fee.
And so that’s another model that is a little bit more restrictive.
At the same time, they have free tools for high schools and for educational use, something called Eyewitness that has something like 3,000 unedited testimonies that are openly available.
So, they still provide thousands of complete unedited testimonies, but the vast majority of the collection is behind a paywall.
And then you see the other Fortunoff Video Archive, which has digitized its entire collection now.
But for decades, its collection was only accessible at Sterling Memorial Library in the Manuscripts and Archives Department in the reading room at Yale University.
So you’d have to make the pilgrimage to New Haven to work with this material.
And so that’s also in a sense, very restrictive.
Not everyone can afford, not all researchers can afford to make the trip to New Haven to do that type of work.
But there’s no costs involved with using the collection.
So in a sense, it’s open to everyone.
And that’s how it worked at Yale.
And so that was a bit restrictive.
But now we’ve also opened up now, now that the collection is digital, and making it available at these access sites, I already said more than 200 of them, but still, it’s not like we’ve thrown it all up online like US Holocaust Memorial Museum.
It’s still kind of like a closed fist that’s kind of slowly opening, right?
And it’s only accessible at these access sites.
It’s free, so the access sites don’t have to pay a subscription fee, but they still have to sign a memorandum of agreement with us.
It’s only accessible on IP ranges that are associated with those institutions, so at various universities and research centers.
So there’s still a certain amount of restriction on who can see it when and where.
And we just have a very different model.
And that model of how to use a collection like this comes from, I think, the fact that we were started by survivors themselves and children of survivors.
This organization from the very beginning was very concerned about the well-being of the survivors before, during, and after the interview has been given.
All of the witnesses sign release forms, and in these release forms, it clearly states that Yale University owns copyright to the recording.
We can do, theoretically, legally, whatever we’d like, but that doesn’t mean we should.
And there was always a sense that the survivors, although they quite clearly wanted to share their story with us and in a very public manner by giving testimony, they still deserve some modicum of privacy and anonymity.
And so we’ve been fairly restrictive in terms of not making it widely accessible online.
etera, but could survivors in: 1981
That’s what the internet is.
And that feels like a step too far without any kind of mediation for us.
Chris Lacinak: 43:53
You also talked about 200 access sites.
Could you tell us what are those?
Who are they?
How do they work?
What does that look like?
Stephen Naron: 44:01
Yeah.
I mean, I did want to say actually something else about some of the ways in which we, the collective places certain restrictions on access that might seem a little strange or idiosyncratic.
Another example that I forgot to mention was, yeah, so things are slightly locked down in a sense they’re only available at access site.
But another thing that’s really unusual about this collection is we also truncate the last names of the survivors.
So if you were to search the metadata, if you were to go to Aviary and search, you would see very quickly that the testimonies are, the titles of the testimonies are, you know, Stephen N.
Holocaust Testimony, Chris L.
Holocaust Testimony.
The last names are hidden from view.
And obviously once you’re at an access site and you’re watching the testimony and the person introduces themselves, you hear their name, you hear their last name.
And in the transcript, if they say their last name, it’s transcribed there, but you don’t see the transcript unless you’re at an access site either.
And the reason behind this was in the early days, one of the survivors full name appeared in a documentary film that was screened on television.
And the survivor received threatening phone calls after the film was screened.
And after that, they decided that this was a risk that they were unwilling to take and push to truncate the last names in order to protect the survivor’s anonymity.
Of course, if you do research, it’s not foolproof.
If you make the effort to come and do the research, you can find out all this information, personal information.
But the idea was to provide some basic hurdle that would provide some protection.
And as you can imagine, that’s served its purpose well, but it also complicates the research process for the research community.
If you’re a researcher and you’re looking for a very specific person who you know gave testimony, it’s much harder to locate them.
Can’t just search for their last name and find them.
So that’s an example of things that might seem sort of counterintuitive.
We did this, though, to protect the survivors.
And what we saw was our first ethical obligation.
And then we have the obligation to the research community, which comes second.
And that’s also a little bit unusual for an organization such as ours.
But you had a question about beyond this sort of access, what the access sites were or how they worked.
So the access sites are mostly universities and research institutions.
So Holocaust museums all over the world, South America, North America, Israel, Europe.
We even have an open access site in Japan.
And the access sites sign a memorandum of agreement that clearly states what they will and what they can and cannot do with the collection.
They provide us with their IP ranges.
So we restrict the collection to an IP whitelist of all of the IP ranges at these institutions.
So you either have to be on campus to watch the testimonies or you have to use a VPN that you only students and faculty will have.
Everyone has to register in Aviary, our access and discovery system.
And that was one of the, when we helped develop this Aviary, that was one of our major requirements was that we would have some ability to control who sees what, when, where, and how.
And so we force everyone to register in our collection and ask for permission to view testimonies before they’re given sort of free access to everything.
And so it’s a very protective model.
In some ways it seems to, I would guess, be in tension with the way a lot of other libraries and archives work where you want to have the anonymity of the user is just as important as the materials that they’re using.
But because we have this, such sensitive materials in this collection, we felt we needed some extra level of control and protection.
Chris Lacinak: 48:41
Relative to what you described earlier, folks had to come to New Haven.
I mean, it’s hugely opened things up.
That’s been a major transformation in that regard, it sounds like.
Among the users, you have proactively been a big user.
You’ve been extraordinarily prolific.
I mean, you’ve talked about not just in the creation of co-creating of Aviary, but you’ve also created a podcast, I believe, from the collections.
You’ve done an album, which you pressed on vinyl, which was not from the testimonies, but was related to the testimonies.
You have these fellowship programs, you do speaker series, you do film series, you do all sorts of stuff.
Can you talk a little bit about, maybe, you know, there’s a lot to talk about there.
You don’t have to go through each one, but maybe tell us about the podcast and the album that you did.
I’d love to hear a little bit more about that, or if there’s any other of those that you’d really like to highlight.
Stephen Naron: 49:35
In interest in various historical topics, there’s always a kind of ebb and flow, right?
And so, I think, to a certain extent, there can be a sort of complacency about, well, this is an amazing collection, without a doubt.
Researchers will come to us.
But I think that times have changed, and that the research community now expects you to sort of come to them.
And that’s a real fundamental shift in the way we think.
And yeah, as you mentioned, we have the fellowship program.
We have a film grant project where we provide a grant to a filmmaker in residence who then creates a short edited program based on testimonies from the collection.
We have a lot of events and conferences that we support that are designed to sort of lift up the collection in both the public eye, but also among the research community.
We’ve done our own productions based on the testimony.
So the podcast series is already in its third season.
We’re planning to do a fourth season.
And this podcast series is really just, again, like I said, we’ve always sort of embraced new methods and new technologies.
And this really just seemed like the ideal way to bring audiovisual material to a new listenership, to the non-research listenership.
I’m obviously a big fan of podcasts, and I’ve been listening to a number of podcasts that were based on oral history collections.
And there’s one in particular that I stumbled upon called Making Gay History, which is based on the oral histories that Eric Marcus recorded with leading figures in the LGBTQ community.
And I don’t know a lot about this topic.
This is not an area that I know a lot about.
And I found it one of the most compelling podcasts I’ve ever heard based on these archival recordings.
And I said, “Okay, well, we should do something like this.”
And so I asked Eric Marcus if he’d be willing to help produce a series for us.
And he also just happens to be a nice Jewish boy from New York.
And so he agreed and found a team to support him, another co-producer, Nahanni Rous.
And they’ve been producing edited versions of the testimonies in podcast form now for three seasons with quite a bit of success.
You know, over 100,000 downloads and streams on Spotify.
And so these are listeners that would probably never stumble into Aviary at an access site and use the collection that way.
They might find some of our edited programs on our website or on YouTube, but this is just another way to push these voices out into the public.
Chris Lacinak: 52:59
And that podcast for listeners is “Those Who Were There” is the name of that podcast, right?
Stephen Naron: 53:03
Yeah, “Those Who Were There.”
The latest…
And if you go to our website or Google “Those Who Were There,” you’ll find it.
You can listen to it on the website as well as on all your podcast apps.
But the website has a lot of other additional information, including episode notes for each episode that are written by a renowned scholar, Professor Sam Kassow, who provides additional context about each episode, which is really valuable, and further readings.
This that we’ve gotten from the family’s scanned images from family archives.
So it’s a really…
I think it’s, you know, on the one hand, it’s a little strange because you’re taking a video testimony and removing the video and making it into audio in order to do this.
So it feels like you’re losing something, obviously, in this transformation.
But you also gain something because as you know, if you listen to podcasts, you know, when it’s just you and a pair of headphones and you’re walking down the street listening to a podcast, you just sort of disappear into your head and it’s very intimate as well.
So I think it’s appropriate, although there is something lost and something gained.
And then you said the songs project.
So that’s called “Songs from Testimonies.”
It’s also available on our website.
And that’s really a…
It really started as a kind of traditional research project.
So one of our fellows, Sarah Garibova, discovered some really unusual songs that were sung in a testimony that we’d never heard before when she was creating her critical edition.
And we found the song so compelling that we asked a local ethnomusicologist in New York and a musician himself to come and perform the songs at a conference as a sort of act of commemoration.
And we were just blown away by the results and thought that we need to do more of this.
And so it became both an ethnomusicological research project, but also a performative project.
So Zisl Slepovitch is our musician in residence, and he’s moved through the collection, locating testimonies with song, sometimes fragmentary songs that were interwar songs, religious songs, songs that were written in ghettos and camps that may be very well-known, but may also be completely unknown.
And he’s done the research, and then he’s performed these songs.
He’s created his own notation or his own composition for each of the songs and performed them.
And we’ve recorded them with an ensemble, and they’re now available for listening.
And there’s been concerts.
We’ve performed the songs several times in concert with the context, showing excerpts from the testimonies.
Where does the song come from?
Explaining how the song emerges and the meaning of the lyrics.
And yeah, so it’s a research project.
It’s a performance project.
It’s a commemorative project.
It’s also a really valuable learning tool.
It’s a way for the general public to enter into a difficult topic and learn a lot about testimony.
So it’s been a pretty rewarding project.
Chris Lacinak: 56:30
Such a beautiful story.
I love that.
And I also know that you pressed it on vinyl as well, didn’t you?
Stephen Naron: 56:39
Yeah, well, because I’m a music nerd.
So this was…
Well, and I mean, also, I’m an archivist, and vinyl lasts a really long time.
So my thought was that if we press it on vinyl, it will last longer if we do it on CD.
We also do it on CD, and it’s available in all the streaming services as well.
But it is a work of art.
We had a local letterpress artist, Jeff Mueller, who runs Dexterity Press.
He printed each of the sleeves by hand.
And they were designed by this incredible Belarusian artist, Yulia Ruditskaya.
And she did all the design work.
She actually created an animated film around one of the songs as well.
There’s more information.
She was one of our Vlock fellows.
It’s on our website as well, the Filmmaker in Residence Fellowship.
So yeah, it’s a really interesting project.
And I’ve learned a lot about the value of music as a historical source through this effort.
But also the music itself is just quite beautiful.
These are world-class musicians performing these pieces.
It’s really something to listen to.
Chris Lacinak: 58:01
So I’d like to circle back to the discussion around the other Holocaust testimony archives and collections that exist out in the world.
To someone that’s an outsider to the nitty-gritty details of all that, and you gave us some good insights into what some of the variances and variables are there.
But it would seem that as a naive user who is interested in researching Holocaust testimonies, that I might be able to go to a single place and search across all of these various collections, or at least a number of them.
Does that exist?
Is that in the works?
Is there discussions amongst the various entities that hold and manage collections?
Stephen Naron: 58:48
Well, what I would say to that naive researcher is, there absolutely should be something like that.
And it is a shanda that there isn’t.
And yeah, there are discussions about how to make that possible.
And there have been some small attempts.
But at this point, I think my description as well of the different organizations and their different sort of policies around access also point to the underlying problem here, which is that all of these organizations are unique individual organizations with policies and procedures and politics that can prevent them from playing nicely with one another.
And I certainly include the Fortunoff Video Archive.
We’re not any– I’m not excluding us from this, right?
So it’s not about the technology.
The technology is very much there to make it possible for a sort of single search across testimony collections that would reveal results for the research community.
And I think it absolutely has to be the next step.
And not just for the research community, but for the families.
One of the most infuriating things, I think, for children and grandchildren of survivors is they don’t know where their grandparents’ testimony is.
Which archive is it in?
They have no simple way to find it.
And that seems to me to be a major disservice to the families of the survivors who, at great emotional risk, gave us their testimony.
So we really need to find a way to do that.
And we need to work together across organizations to make that happen.
US Holocaust Memorial Museum has also made some really important inroads in this regard.
They have something called Collection Search, where they’ve added metadata from the USC Shoah Foundation, their metadata, and the Fortunoff Video Archives metadata, since they have access to our collection on site at USHMM, into their collection search.
So that’s the first search engine I’ve seen where you can actually search across USHMM, USC, and Fortunoff and find testimonies that are related.
And we’re also doing it in Aviary to a certain extent.
So in Aviary, we’ve got a couple of different organizations with testimonies that have joined together to create what’s called in Aviary a Flock.
And so it’s a way to search across.
It’s like a portal that can search across different collections in Aviary.
ings of survivors recorded in: 1946
And a number of other organizations that have audio and video testimonies in Aviary, and you can search across those as a collective.
And so there are plenty of examples of this working.
We’ve also got a, we formed a digital humanities project that brought together transcripts over a three, I think 3,000 testimony transcripts of survivor testimony from Fortunoff, USHMM, and USC Shoah Foundation, and a project called Let Them Speak.
And you can search across the transcripts of all those collections.
And that’s pretty, that’s also a step, again, another example of what would be possible.
Imagine a world in which everybody just finally shared their testimonies.
So we have a lot of examples of how this works and the benefits of it, but we don’t have like a, we don’t have, it’s almost like we need an umbrella organization that would pull all of these disparate groups together and make them agree on how to share metadata in a way that everyone can have access to it.
Chris Lacinak: 62:51
Right.
Stephen Naron: 62:52
We’re not there yet.
Chris Lacinak: 62:53
Yeah.
Okay.
So some glimmers of hope, but not quite there yet.
Stephen Naron: 62:56
Yeah.
Chris Lacinak: 62:57
Switching gears, I want to ask a question.
I recently had Bert Lyons on the show and we talked about content authenticity.
And I guess I wonder, I mean, this is an issue for every archive, but given the focused efforts around Holocaust denial and things like that, I wonder how you’re thinking about the prospect of fakes and forgeries in the age of AI when, you know, it’s not a new issue.
Fakes and forgeries have been issues for archives for as long as archives have been around, but just the ability and capability of people to create content now to support false narratives and cause issues for archives like yourself.
I wonder, is that something that’s getting talked about within Holocaust testimony circles or is that still on the horizon?
Stephen Naron: 63:54
As technology improves or changes and is more sophisticated and these AI tools become more sophisticated, yes, certainly that’s a new risk, but there are also new technologies and tools to identify things that are fake.
So the technology brings with it new types of artifacts and ways to see whether or not this is testing the authenticity of a digital object.
I’m sure that’s way beyond my, I can’t really talk about that because that’s beyond my field of expertise.
But in my area, I mean, really the more dangerous thing instead of like outright denial, which has always existed but is really limited to the margins, is something that you’ve seen more and more of, which is not outright denial, but a kind of half-truth or willful manipulation of the facts to sort of, it’s like denial light.
It’s bad history being sort of marketed as authentic history in order to pursue a particular ideological or political end, right?
So you see this a lot in, not to pick on anyone in particular, but in certain regimes in Europe that have been considered more, have taken a sort of more populist, authoritarian turn, there have been quite obvious attempts to replace traditional independent scholarship with scholars who are being sort of controlled, funded, supported by the state and the government in a way and sort of asked to willfully, willingly misrepresent the truth, right?
So they still cite historical sources, but they cite them in a way that would not be sort of attempted objective historical writing, right?
In order to tell a story that is inaccurate, let’s say that Polish citizens were not complicit in the Holocaust and every Polish village was filled with individuals who were willing to hide and save Jews from extinction.
These types of sort of exaggerations and misrepresentations of sources, that’s becoming a much greater threat than outright denial.
Also because it’s difficult, because the way it’s shaped, it looks like scholarship, looks like research, it’s presented from official organizations that just happen to be corrupted.
And so that becomes much more of a difficult thing to push back on, but you can and scholars do that and that’s exactly what good scholars do is they push back on this stuff.
But yeah, the AI, considering this is an audiovisual collection exclusively at the Fortunoffe archive, it seems pretty frightening what would be possible.
Chris Lacinak: 67:45
Right.
Well, first point well taken.
I mean, it sounds like let’s not focus too much on the nitty gritty of AI at the sacrifice of recognizing the larger issues, which are much broader than that.
So I really hear what you say there and appreciate those comments.
Here’s one of the things I think about, I mean, the kind of quick scenario you threw out was like someone creates something fake and their tools to identify things as fake.
And that’s true.
I think what’s almost more worrisome for me, and I think that every archive will need to kind of arm themselves with, and there are technologies to do this, at least if not today, then on the near horizon, but is to be able to combat claims of things that are authentic, that are held within an archive, which people claim are fake, and they have to prove that they’re authentic.
Right?
Like that is when people start to cast doubt about authentic things being fake, that’s almost more worrisome to me than someone creating something fake and having to prove that it’s fake or saying that it’s authentic.
Stephen Naron: 68:58
Yeah, absolutely.
And that sort of reminds me of the same kind of bad history that I was trying to describe, like these sort of willful manipulation of the sources that exist and claiming they’re either inauthentic or sort of misrepresenting, misquoting them or quoting them selectively in order to make an argument that’s unsound.
I mean, that’s absolutely true.
That seems like a tactic that could be used.
I mean, at the Fortunoff Video Archive, we can at least point to a chain of, you know, a provenance chain that takes us all the way back to the original master recordings, which are still in cold storage at, you know, in New Haven, right?
So actually I think they’re in Hamden at our storage facility there.
Chris Lacinak: 69:55
For those New Haven geography buffs.
Stephen Naron: 69:59
Yeah, I didn’t want anyone to, it’s not fair.
It’s in Hamden.
But yeah, so I mean, we have a chain that we can then show the sort of authentic steps that were taken.
And even in the digitization process, there was great care given to the sort of SAMMA systems document the whole digitization process.
And so what’s happening as the signal sort of changes over time.
And so you also have a pretty, you have like a record of the actual transfer and can show if there’s been interruptions or not, lack of interruptions and things like that.
So that’s a pretty detailed level of authenticity control.
Chris Lacinak: 70:43
So Stephen, one of the things that I want to do with this podcast is to back up out of the weeds and reflect on why the work that we do is important to remind ourselves to rejuvenate on purpose and meaning of this work.
And with that in mind, I wonder if you could reflect on the importance and the why behind the Fortunoff Video Archives work.
Why is it important?
Stephen Naron: 71:10
Well I think that it’s important for a couple of reasons.
I’ll just give you three.
Well first of all, the Holocaust is quite possibly the greatest crime committed in the 20th century and one of the greatest crimes in history.
And as such, the brutality of the Holocaust has really impacted our society on so many levels.
So from a kind of universal perspective, we’re still very much living in a world that was shaped by the impact of the Holocaust and the Second World War.
Our belief in these ideas of universal human rights, etc., and of course our inability to always adequately support the regime of human rights internationally, this is directly related to the events of the Holocaust.
And so if you really want to understand the world in which we’re living today, you cannot do so without approaching the history of the Holocaust.
And the history of the Holocaust needs to be approached by every generation in a new way.
And having an archive such as this is one of the best ways, working and engaging with an archive such as this is really one of the best ways to approach this topic.
It’s also important, and the work we do is important, because I think the archive is something of a living memorial to those who did not survive, right?
So the survivors themselves are really the anomalies.
They’re the lucky ones.
And the vast majority of European Jewry was murdered, 6 million men, women, and children.
And so I really see this archive as a sort of living memorial to both the survivors and those who did not survive, their families who did not make it.
And so the archive can serve as a bridge between the living, us, and the dead.
And in fact, as time progresses, and we’re beginning to reach an era where there will no longer be any living witnesses of the Holocaust, due to just simply demographic change, the archives, and archives like this one of testimonies of Holocaust survivors will only become that much more important.
It will be the only way in which we can really engage with personal stories of the witnesses.
Only diaries and memoirs and testimonies like this can give us access to what it felt like to be there in the war, in the camps, in the ghettos, and to have survived.
And then I think the work we do is important as, first of all, as an act of solidarity with the survivors and witnesses themselves.
And as an act of solidarity, it really has served as a model for what I would call an ethical and empathic approach to documenting the history of mass violence from the perspective of those who were there, the witnesses, right?
So a bottom-up perspective.
And it has served as a model, and it continues to serve as a model for lots of organizations who do the type of important work of documenting human rights and civil rights abuses.
So yeah, so those are just three ways I think that the collection really is a, continues to have an impact and is really an important organization.
Chris Lacinak: 75:04
Steven, thanks so much for joining me today.
It’s been extraordinarily enlightening.
I want to thank you for your work that you do, and it’s just been an amazing, it’s been amazing to hear about the journey of this incredible collection and archive.
So thank you for sharing with us today.
In closing, I want to ask you a question that I ask all of my guests on the DAM Right podcast, which is totally separate from anything we’ve talked about so far today, which is, what’s the last song you added to your favorites playlist or liked?
Stephen Naron: 75:39
The last song I added to my playlist.
Well, I guess I have to stay true to the archives and maybe not be entirely honest and say that one of the last songs I put on my playlist was from the volume three of our Songs from Testimonies project, which is called “Shotns or Shadows.”
And it would be the title track, “Shotns,” which is a Yiddish song.
That’s in my playlist.
And I hope you all listen to it too.
Chris Lacinak: 76:17
Okay, we’ll share the links to that in the show notes.
Can you tell us what the actual last song you put in your playlist was?
Stephen Naron: 76:24
It’s actually, you know, usually it’s whole albums.
I put whole albums in my playlist.
Is a Greek avant-garde musician named Savina Yannatou, who I stumbled upon.
Yeah, the song is called something in Greek, which I will not mispronounce for your audience.
Chris Lacinak: 76:48
I’ll get the link from you so we can share it with everybody.
Wonderful.
All right, well, Stephen, thank you so much.
You’ve been extremely generous with your time and all your insights.
Thank you very much.
I appreciate you taking the time.
Stephen Naron: 76:59
No problem.
Thank you, Chris.
Chris Lacinak: 77:00
Thanks for listening to the DAM Right podcast.
If you have ideas on topics you want to hear about, people you’d like to hear interviewed, or events that you’d like to see covered, drop us a line at [email protected] and let us know.
We would love your feedback.
Speaking of feedback, please give us a rating on your platform of choice.
And while you’re at it, make sure that you don’t miss an episode by following or subscribing.
You can also stay up to date with me and the DAM Right podcast by following me on LinkedIn at linkedin.com/in/clacinak.
And finally, go and find some really amazing and free resources from the best DAM consultants in the business at weareavp.com/free-resources.
You’ll find things like our DAM Strategy Canvas, DAM Health Scorecard, and the Get Your DAM Budget slide deck template.
Each resource has a free accompanying guide to help you put it to use.
So go and get them now.
The Critical Role of Content Authenticity in Digital Asset Management
11 April 2024
The question of content authenticity has never been more urgent. Digital media has proliferated, and advanced technologies like AI have emerged. Distinguishing genuine content from manipulated material is now crucial in many industries. This blog examines content authenticity, its importance in Digital Asset Management (DAM), and current initiatives addressing these challenges.
Understanding Content Authenticity
Content authenticity means verifying that digital content is genuine and unaltered. This issue isn’t new, but modern technology has intensified the challenges. For example, the FBI seized over twenty-five paintings from the Orlando Museum of Art, demonstrating the difficulty of authenticating artworks. Historical cases, like the fabricated “Protocols of the Elders of Zion,” reveal the severe consequences of misinformation. Digital content’s ubiquity makes it vital for organizations to verify authenticity. Without proper measures, content may remain untrustworthy.
The Emergence of New Challenges
Digital content production has skyrocketed in the last decade. Social media rapidly disseminates information, often without verification. Generative AI tools create highly realistic synthetic content, complicating the line between reality and fabrication. Deepfakes can simulate real people, raising serious concerns about misinformation. Organizations must combine technology with human oversight to navigate this complex environment.
The Role of Technology in Content Authenticity
Technology provides tools to detect and address authenticity challenges. Yet, technology alone isn’t enough. Human expertise must complement these solutions. The Content Authenticity Initiative (CAI), led by Adobe, is one effort creating standards for embedding provenance data in digital content. The Coalition for Content Provenance and Authenticity (C2PA) also works to embed trust signals into digital files. These efforts enhance content verification and authenticity.
Practical Applications of Content Authenticity in DAM
For organizations managing digital assets, content authenticity is crucial. DAM systems benefit from integrating authenticity protocols. Several practical applications include:
- Collection Development: Authentication techniques help evaluate incoming digital assets.
- Quality Control: Authenticity measures verify file integrity during digitization projects.
- Preservation: Provenance data embedded in files ensures long-term reliability.
- Copyright Protection: Content credentials protect assets when shared externally.
- Efficiency Gains: Automating authenticity data reduces manual errors.
The Risks of Neglecting Content Authenticity
Neglecting content authenticity poses significant risks. Misinformation spreads quickly, damaging brands and eroding public trust. Sharing manipulated content can lead to legal issues and financial losses. Ignoring authenticity can have severe consequences, including reputational and legal liabilities.
Collaboration and the Future of Content Authenticity
Collaboration is vital for achieving content authenticity. Organizations, technology providers, and stakeholders must develop best practices together. The rapidly evolving digital landscape demands ongoing innovation. Investing in authenticity technologies and frameworks will become essential.
Case Studies: Content Authenticity in Action
Organizations are already implementing successful authenticity measures. Media outlets verify user-generated videos and images with specialized tools. Human rights organizations embed authenticity data into witness-captured files, ensuring credibility in court. Museums and archives verify digital assets’ provenance, preserving their integrity.
Conclusion: The Imperative for Content Authenticity
Content authenticity is a societal necessity, not just a technical issue. As digital content grows, verifying authenticity will be vital for maintaining trust. Organizations that prioritize content authenticity will navigate the digital age more effectively. Collaboration and technology will ensure digital assets remain credible, trustworthy, and protected.
Transcript
Chris Lacinak: 00:00
Hello, welcome to DAM Right, Winning at Digital Asset Management. I’m your host, Chris Lacinak, CEO of Digital Asset Management Consulting Firm, AVP. In the summer of 2022, the FBI seized more than 25 paintings from the Orlando Museum of Art based on a complex, still unclear scheme to legitimize these supposedly lost and then found paintings as the works of Basquiat. In 1903, the Protocols of the Elders of Zion was published, detailing a series of meetings exposing the Jewish conspiracy to dominate the world. It was used in Nazi Germany and by anti-Semites worldwide to this day as a factual basis to promote and rationalize anti-Semitism. Of the many problematic things regarding this text, one of the biggest is that it was a complete work of fiction. In 2005, an investigation conducted by the UK National Archives, identified a number of forged documents interspersed with authentic documents posing as papers created by members of the British government armed services, tying them to leading Nazi figures. No one was convicted, but three books by the author, Martin Allen, cited these forged documents and documentation shows that he had access to these specific documents. In 1844, an organized gang was convicted in London for creating forged wills and registering fictitious deaths of bank account holders that the gang had identified as having dormant accounts so that they could collect the remaining funds. As this sampling of incidents demonstrates, content authenticity is not a new problem. It is, however, a growing problem. The proliferation of tools for creating and altering digital content has amplified the authenticity dilemma to unprecedented levels. In parallel, we are seeing the rapid growth and deployment of tool sets for detecting fake and forged content. As is highlighted in this conversation, the line between real and fabricated lies in the intent and context of its creation and presentation. This conundrum signals that technology alone cannot bear the weight of discerning truth from fiction. It can merely offer data points on a file’s provenance and anomalies. As the hyperspeed game of cat and mouse continues on into the foreseeable future, it’s also clear from this conversation that addressing this challenge in any truly effective way requires an integrated and interoperable ecosystem that consists of both people and technology. The stakes are high touching every industry and corner of society. The ability to assert and verify the authenticity of digital content is on the horizon as a cornerstone of digital asset management, as well as being a social imperative. Amidst this complex landscape of authenticity, integrity, and technological chase, I am excited to welcome a vanguard in the field, Bertram Lyons, to our discussion. As the Co-Founder and CEO of Medex Forensics, an Illuminary in content authenticity, Bert’s insights are extraordinarily valuable. His journey from a Digital Archivist at the American Folklife Center at the Library of Congress to spearheading innovations at Medex Forensics underscores his deep engagement with the evolving challenges of digital veracity. Bert’s involvement in the Content Authenticity Initiative and the C2PA Working Group, coupled with his active roles in the American Academy of Forensic Sciences and the Scientific Working Group on Digital Evidence, highlight his commitment to shaping a future where digital authenticity is not just pursued, but attained. Join us as we explore the intricate world of content authenticity, guided by one of its esteemed experts.
Bertram Lyons, Welcome to DAM Right. I’m so excited to have you here today. Uh, um, I’m particularly excited at this moment in time, because I feel like the expertise and experience you bring is going to be a breath of fresh air, um, that gives us a deeper dive into the nuance and details of a topic, content authenticity, which I think is most frequently, uh, experienced as headlines around, uh, kind of bombastic AI sorts of things, and I think that, uh, you’ll, you’ll bring a lot of clarity to the conversation. So thank you so much for being willing to talk with us today. I appreciate it.
Bertram Lyons: 04:27
Thanks Chris.
Chris Lacinak: 04:28
I’d like to start off with just talking a little bit about your background. I think it’s fair to say that you didn’t come to forensics and content authenticity with the most typical background. I’d love to hear a bit about how you arrived here and how the journey, uh, kind of informed what your approach is today.
Bertram Lyons: 04:47
To give you a sense of, you know, where I think I am today is working in the world of, uh, authenticating digital information, uh, specifically video images. Um, and how I got there, you know, I spent 20 years plus working in the archives industry. That was really what, what I spent my time doing up until a few years ago. Um, I started at, you know, various different kinds of archives, um, one. exciting, um, uh, place that I worked for, for a variety of years. When I first started out, it was a place called the Alan Lomax Archive. And that was a really cool audiovisual archive. You know, it had tons of formats from, from the start of recording technology up until the time that, that particular individual, Alan Lomax, stopped recording, which spanned from like 1920s through the . 1990s So, you know, really a lot of cool recording technology. And I did a lot of A. D. analog to digital conversion at that time. Um, and that led me down a path of really ultimately working in the digital side of, of archives and ending up at the Library of Congress in D. C. where I, where, you know, my job was specifically a Digital Archivist, and my job there was to learn and understand how historical evidence, um, how it existed in digital form. Um, to document that and to be able to establish strategies and policies for keeping that digital information alive as, as long as possible, both, both the bits on one side and the, um, and the information itself on, on the other side and ensuring that we can, we can reverse engineer information as needed as, as time goes on, uh, so we don’t lose the information in our, in our historical collections. So, uh, it’s been many years with that and then, you know, jumped out, jumped ship from, from LC and started working with you, uh, at AVP and, uh, you know, for a number of years. And that was an exciting ride where we applied a lot of that knowledge, you know, I was able to apply a lot of my experience to our, our customers and clients and colleagues there. Um, but ultimately the, the thing that brought us, brought me into the digital evidence world where I work now was through a relationship that we developed with the FBI and their Forensic Audio Video Image Analysis Unit, um, in Quantico where, you know, we were tasked to increase capabilities, you know, help that team there who, who were challenged with establishing, , authenticity of evidence for court and help them to increase their ability to do that, uh, both manually using their knowledge about digital file formats, but also ultimately in an automated way because Unfortunately, and fortunately, digital video and image, um, and audio are, just everywhere, you know, there’s just so much video, uh, image and audio data around that it becomes the core of almost every investigation that’s happening. Um, any question about what happened in the past we turn to multimedia
Chris Lacinak: 07:43
I think back to you sitting at the American Folklife Center and Library of Congress. Did you ever have any inkling that one day you’d be working in the forensics field? Was that something you were interested in at the time or was it a surprise that kind of to you that you ended up where you did?
Bertram Lyons: 07:57
on my mind in that when I, in: 2000
Chris Lacinak: 10:22
Transitioning a bit now away from your personal experience, I, I guess in preparing for this conversation, it dawned on me that content authenticity is not a new problem, right? That there’s been forgeries and archives and in museums and in law enforcement situations and legal situations for, for centuries, but but it does seem very new in its characteristics. And I wonder if you could talk a bit about like what’s happened in the past decade that makes this a much more urgent problem now, uh, that it deserves the attention that it’s getting.
Bertram Lyons: 10:57
I think, you know, you say the past decade, a few things that I would put on the table there. One would be just entirely. the boom, which is more than a decade old, but the boom in social media and that like, and that the how fast I can put information out into the world and how quickly you will receive it, right? Wherever you are. So it’s just the, the ability for information to spread And information being whether it’s, whether it’s a, you know, media like image or audio or video or whether it’s, you know What I’m saying in text. Those are different things too, right? So just to scope it for this conversation, just thinking about the creative or documentary sharing of image, video, and audio, right? So it’s a little bit different probably when we talk about misinformation on the tech side. But when we talk about content authenticity with media things, you know, it can go out so quickly, so easily, from so many people. That’s a, you know, that’s a huge shift from years past where we’re worried about the authenticity of a photograph in a, in a museum, right? That’s a, the reach and the, uh, the immediacy of that is, is significantly different, um, in today’s world. And then on, uh, I was, I would add to that, now the ease with which, and this is more of the last decade, with which the, uh, individuals have access to creatively manipulate or creatively generate, you know, new media, That can be confused with, from create, from the creative side to the documentary side. Can be confused with actually documentary evidence. So, you know, the content’s the same whether I create a video of, you know, of myself, um, you know, climbing a tree or whatever. Um, that’s content and I could create a creative version of that that may not have ever happened. And that’s for fun and that’s great. We love creativity and we like to see creative imagery and video and audio. Or I could create something that’s trying to be documentary. You know, Bert climbed this tree and he fell out of it. Um, and that really happened. I think the challenge is that we’re starting, the world started, the world of creating digital content is blending such that you wouldn’t be able to tell whether I was doing that for, from a creative perspective or from a documentary perspective. And then, you know, and I have the ability to share it and claim one or the other, right? And so the, the, those who receive it now, out in the social media world and the regular media world, you know, have to make a decision. How do I interpret it?
Chris Lacinak: 13:31
Yeah
Bertram Lyons: 13:31
But I think the core challenge that we face off the authentication side is still one of intent by the individual who’s, who’s creating and sharing the content. The tools have always been around to do anything you really want to digital content, um, whether it’s a human doing it or, or asking a machine to do it. In either scenario, what’s problematic is the intent of the person or group of people creating that, and how they’re going to use it.
Chris Lacinak: 14:04
What do you think people misunderstand most about the topic of content authenticity? Is there something that you see repeatedly there?
Bertram Lyons: 14:11
From the way the media addresses it generally, I think one of the biggest misinterpretations is that synthetic media is inherently bad in some way. that we have to detect it because it’s inherently bad, right? You get this narrative, um, that is not true. You know, it’s, it’s a creation process, and it inherently is not a, uh, it doesn’t have a bad or a good to it, right? It comes back to that question of intent. Synthetic media or generative AI that’s creating synthetic media is really just allowing a new tool set for creating what you want to create. We’ve been looking at CGI movies for years and how much of that is ever real. Very little of it, but it’s beautiful and we love it. It’s entertaining. And it comes back to the intent. On the flip side, another really, I think, big misunderstanding in, in this is that, this really comes down to people’s understanding of how files work and how they move through the ecosystems that they’re, that they’re stuck in. You know, files themselves don’t live except for within these computing ecosystems. They move around, they get re-encoded, they, um, and as they follow the, that lifecycle, they get interacted with by, by all kinds of things. Um, like by encoders that are changing, uh, the resolution, for example, or encoders that are just changing the packaging. Um, those changes, which are invisible to the, to the average person, those changes are actually extremely detrimental to the ability to detect synthetic media, or anything that you want to detect about a, about a, you know, that content. As that content gets moved through, it’s being normalized, it’s being laundered, if you will, um, into something that’s very basic. Um, and, and as that laundering happens, that particular content and that particular packaging of the file becomes in some ways useless from a forensic perspective. And I think the average person doesn’t get that yet. That information is available to them. That, that if you want to detect if something’s synthetic and it’s sitting on your Facebook feed, well it’s too late. Facebook had the chance on the way in, and they didn’t do it, or they did do it. Um, and now we’re stuck with like network analysis stuff. Who did, who posted that? Now we’re going back to the person. Who posted that? Where were they? What was their behavior pattern? Can we trust them? Versus, you know, having any ability to apply any trust analysis unless it’s a blatantly visual issue to that particular file.
Chris Lacinak: 16:45
Can you give us some insights into what are some of the major organizations or initiatives that are out there that are focused on the issue of content authenticity? What’s the landscape look like?
Bertram Lyons: 16:55
From the content authenticity perspective. It’s a lot, a lot of it’s being led by, major technology companies who, who, who trade in content. So that could be from Adobe, who trades in content creation. Could to Google, who trades in content distribution and searching. Um, you know, and everybody in between. Microsoft, Sony, you know, organizations who are either creating content. Whose tools allow humans to create content and computers or, uh, organizations who really trade in the distribution of that content. Um, so there’s, there’s an organization that’s composed of a lot of these groups called the Content Authenticity Initiative. Um, and there’s, it’s, that, that organization is really heavily led by Adobe. Um, but has a lot of other partners involved with it. And then it sort of has become an umbrella for, for, for, uh, I’d say an ecosystem based perspective on content authenticity that’s really focused on, um, the ability to embed what they’re calling content credentials, but ultimately to embed signals of some sort, whether it’s actual text based cryptographic signatures, whether it’s watermarking, other kinds of, there’s other kinds of approaches, but ultimately to embed signatures, or embed signals in digital content. Such that as it moves through this ecosystem that I mentioned earlier, you know, from creation on the computer, to upload to a particular website, to display on the web, through a browser. It’s really focused on like, can we, can we, can we map the lifecycle of, of a particular piece of content? Um, can we somehow attach signals to it such that as it works its way through, um, it can, those signals can be read, displayed, evaluated, and then ultimately a human can determine how much they trust that content.
Chris Lacinak: 19:00
If I’ve got it right, I think the Content Authenticity Initiative are the folks that are creating what’s commonly referred to as C2PA or the coalition for content provenance and authenticity. Is that right?
Bertram Lyons: 19:12
That’s right. Yeah, that’s like the schema,
Chris Lacinak: 19:15
Okay.
Bertram Lyons:: 19:15
technical schema.
Chris Lacinak: 19:16
And in my reading of that schema, and you said this, but I’ll just reiterate and try to kind of recap is that it looks to primarily identify who created something. It really focuses on this concept of kind of trusted entities. Um, and it does offer, um, as you said, provenance data that it will automatically and or systematically embed into the, uh, files that it’s creating. And this starts at the creation process, goes through the post production and editing process through the publishing process. Is that a fair characterization? Is there anything that’s kind of salient that I missed about, uh, how you think about or describe that, uh, schema?
Bertram Lyons: 20:03
I think that’s fair. I think the only thing I would change in the way you just presented it is that the C2PA is a schema and not software. So it will never embed anything and do any of the work for you. It will allow you to create software that can do what you just said. C2PA itself is purely like a set of instructions for how to do it. And then if you, or if you, uh, you know, want to implement that, you can. If Adobe wants to implement that, they actually already implemented it in Photoshop. If you create something and extract it, you will have C2PA data in it, um, in that file. So it’s really creating a specification that can then be picked up by, um, anybody, any who generates software to read or write, uh, video or images or audio. Actually, it’s really built to be pretty broad, you know. They define ways to package the C2PA data sets into PDFs, into PNGs, into WAVs, you know, generally, um, trying to provide support across a variety of format types.
Chris Lacinak: 21:03
And the provenance data that’s there, or the specification, uh, for, for embedding, uh, creating provenance information is optional, right? It, someone doesn’t have to do it. Is that true?
Bertram Lyons: 21:16
Let me come at it a different way.
Chris Lacinak: 21:18
Okay
Bertram Lyons: 21:18
It depends on what you use. If you use Adobe tools, it will not be optional for you. Right? If you use a, a, a tool to do your editing that’s not working, that doesn’t, hasn’t implemented C2PA, it will be optional. It won’t even be available to you. Um, that’s why I talk about ecosystem. You know, the, the tools you’re using have to adopt, implement this kind of, um, technology in order to ultimately have the files that you export contain that kind of data in them, right? So it’s optional in that you choose how you’re going to create your content, and you have the choice to buy into that ecosystem or actually to select yourself out of that ecosystem. This reminds me of the early days of kind of in just generally speaking embedded metadata, where before everyone had the ability to edit metadata in word documents and PDF documents and audio files and video files and all that stuff. It was a bit of a. black box that would hold some evidence. And there were cases where folks claimed that they did something on such and such a date, but the embedded metadata proved otherwise. Uh, today that feels naive because it’s so readily accessible to everybody. So I kind of, in the same way that, um, there was a time and place where not everybody could access and view and, or write and edit. Uh, and embedded metadata in files, this sounds similar that, that the tool set and the ecosystem, as you say, has to support, um, that sort, that sort of, those sort of actions. Yeah, they’ll have to be able, you’ll have to support it, and I’ll, just, just so, so, somebody listening doesn’t get the wrong idea, C2PA spec is very much stronger than the concept of embedded metadata, and that, it’s cryptographically signed. So, you know, up until C2PA existed, anybody could go into a file and change the metadata, and then just re save the file and no one would ever know. Potentially. Um, but what the, the goal of C2PA actually is to make embedded metadata stronger. Um, and it’s to generate, um, these, this package of a manifest. It says, you know, inside of this file, there are going to be some assertions that were made by the tool sets that created the file and maybe the humans that were involved with the tool set that created the file, they’re going to make some assertions about its history and then they’re going to sign it with the cryptographic signature. They’re going to sign everything that they said such that if anything changes, the signature will no longer be valid, right? So it’s really a goal of trying to lock down inside the file the information that was stated about the file when it was created and to bind that to the, to the hashing of the content itself. So if I have a picture of me, that all the pixels that go into that picture of me get hashed to create a, you know, a single value, um, what we call a checksum. That checksum is then bound to the statements I make about that. I created this on Adobe Premiere, well actually, Adobe Photoshop would make a statement about what I did to create it, you know, it was created by Photoshop, it was, these edits were done, this is what created it, and that’s an assertion, and then I might say, you know, Bert Lyons created it, that’s the author, that’s an assertion, those assertions are then bound to the checksum of the file, of the image itself, right, and locked in, and if that data sticks around in the file as it goes through, um, it’s ecosystem, and someone picks it up at the end of the pathway, they can then check. Bert says he, he created this on this date, using a Photoshop. Photoshop said he did X, Y, and Z. Signature matches, nothing’s been changed. Now I have a trust signal, and it’s still going to be up to the human to say, do I trust that? Is C2PA strong? Is the cryptography and the trust framework strong enough, such that nobody could have, nobody really could have changed that?
Chris Lacinak: 25:16
So this C2PA spec then brings kind of this trust. entity trust level, who created this thing, but it also then has this robust cryptographic, um, signed, uh, kind of provenance data that tells exactly what happened. And it sounds like it is editable, uh, it’s deletable, it’s, it’s creatable, but it’s within the ecosystem that it lives within and how it works, it sounds like that there are protection mechanisms that mitigate, um, intentional, uh, augmentation for, you know, malicious purposes or something that it, that it mitigates that risk.
Bertram Lyons: 25:56
Yeah, I mean, think about it like this. Like it, it doesn’t take away my ability to just go in and remove all the C2PA data from the file. I, I just did that with a file I created for, from Adobe, right? I needed to create a file of my colleague Brandon. I wanted to put a fun fake generative background behind him. And I, I created it and I put some fake background behind them and I exported it as a PNG and I looked in there because I know and I was out of curiosity and so I was like, oh look, here’s the, here’s the C2PA manifest for this particular file. I just removed it. Nothing stops me from doing that. Resaved the file and moved on. Now this file, um, so the way C2PA works, this file now longer, now no longer has C2PA data. It can go down. It can go across, uh, about its life like any other file. And if someone ever wanted to evaluate the authenticity, they’re going to have to evaluate it from without that data in it. They’re going to look at the metadata, they’re going to look at where it was posted, where they accessed it, what was said about it, all of that. The same way that we do for everything that we, we, we interact with today. Um, if that C2PA data had stayed in the file, which I, I, I was just wanting to make sure that I, I’m always testing C2PA, you know, does it still, does the file still work if I removed this, et cetera. Um, but if it stayed in there, it likely would’ve been removed from LinkedIn when I posted it, for example, I posted it up on LinkedIn. Um, it would’ve, it would, it would’ve been removed anyway ’cause the file would’ve been re it reprocessed by LinkedIn. Uh, but if LinkedIn, LinkedIn was C2PA aware, which maybe one day it will be, it would say it would be, and if I left the C2PA data in it and I submitted it to. To, uh, LinkedIn, then LinkedIn would be able to say, oh, look, I see C2PA data. Let me validate it. So it would validate it, and then gimme a report that said, there’s data in here and I validated the checksum, uh, the, or the, the, the signature from the, from C2PA. And now it could display that provenance data for me. It was created by Bert in Photoshop. Um, and it could, again, it all comes around to communicating back to the end user. About the, about the file. Um, now if I had done, tried to make, it doesn’t, still doesn’t stop me from making a malicious change. If I, instead of removing the C2PA data, I went in and tried to change something, that, what would happen? Like maybe I changed the, who created it from Bert to Chris. Um, when that hit, if LinkedIn was C2PA aware, when that hit LinkedIn, LinkedIn would say this has a manifest in it, but it’s not valid. So it would alert me to something being different in the metadata. In the ctpa manifest then from when it was originally created doesn’t keep me from doing it. But now I’m sending a signal to LinkedIn where they’re going to be able to say there’s something invalid about the manifest. That’s kind of the behavioral patterns that happen. So again, it comes back to you. And I went through that example just to show you that still, no matter what we implement, the human has decisions to make on the creation side, on the sharing side and on the interpretation side.
Chris Lacinak: 29:04
Right.
Bertram Lyons: 29:04
Nothing’s really even at this most advanced technological state, which I think C2PA is probably the strongest effort that’s been put, put forward so far. You know, if I, if I want to be a bad actor, I’m going to, I can get around it. You know, I could just, well, I can opt out of it. That’s where it comes down. So the ecosystem is what’s really important about that approach is that the more systems that require it, then, and the less I have to opt out of it, the better. Right? So we’re creating this tool for it to work. It’s about, really about the technological community, buying in and locking it down such that you can’t share a file on Facebook if you don’t, if it doesn’t have C2PA data in it. If LinkedIn said you can’t share something here if it doesn’t have C2PA data, then once I remove the data, I wouldn’t be able to share it on LinkedIn.
Chris Lacinak: 29:54
Right.
Bertram Lyons: 29:55
That’s what’s missing so far.
Chris Lacinak: 29:57
Thanks for listening to the DAM Right podcast. If you have ideas on topics you want to hear about people, you’d like to hear interviewed or events that you’d like to see covered, drop us a line at [email protected] and let us know. We would love your feedback. Speaking of feedback. Please give us a rating on your platform of choice. And while you’re at it, make sure to follow or subscribe so you don’t miss an episode. If you’re listening to the audio version of this, you can find the video version on YouTube using at @DAMRightPodcast and Aviary at damright.aviaryplatform.com. You can also stay up to date with me and the DAM Right podcast by following me on LinkedIn at linkedin.com/in/clacinak. And finally, go and find some really amazing and free DAM resources from the best DAM consultants in the business at weareavp.com/free-resources. You’ll find things like our DAM Strategy Canvas, DAM Health Scorecard, and the “Get Your DAM Budget” slide deck template. Each resource has a free accompanying guide to help you put it to use. So go and get them now. Let’s move on from C2PA. Um, that, that sounds like that covers this, some elements of content authenticity at the organizational level, at provenance documentation level, some signatures and cryptographic, um, protections. You’re the CEO and Founder of a company that also does, uh, forensics work, uh, as you mentioned, Medex Forensics. Uh, could you tell us about what Medex Forensics does? What does that technology do and how does that fit into the ecosystem of tools that focus on content authenticity?
Bertram Lyons: 31:43
The way we approach and, and the contributions that we try to make to the forensics field is from a file format forensics perspective. So if we know how video file formats work, we can accept a video file, we can parse that video file and extract all the data from it and all the different structures and internal sequencing, ultimately to describe the object as an object, as a piece of evidence, like you would if you were handling 3D evidence. Look at it from all the different angles, make sure we’ve evaluated its chemistry, like we really understand every single component that goes to make up this information object called a file. Um, and once we do that, we can then describe how it came to be in that state. How did it come to be as it is right now? If the question was, hey, is this thing an actual original thing from a camera? Was it filmed on a camera and has not been edited? Then we’re going to evaluate it, and we’re not going to say real or fake, true or false. We’re going to say, based on the internal construction of this file, it is, it is consistent with what we would expect from an iPhone 13 camera original file, right? That’s the, that’s the kind of response that we would give back. And that goes back into the interpretation. So if the expectation was, was this an iPhone 13? We’re going to give them a result that matches their expectation. If their expectation was this came from a Samsung Galaxy, and we say it’s consistent with an iPhone 13, that’s going to change their interpretation. They’re going to have to ask more questions. Um, so that’s what we do. We have built a, a, a methodology, uh, that can track and understand how encoders create video files. Uh, and we use that, the, that knowledge to automatically match the internal sequencing of a file to what we’ve seen in the past and introduce that data back. So that’s, that’s kind of where we play. Um, in that world. I’ll, I’ll point out just a couple of things. So we call that non-content authentication. Um, and you would also want to employ content based authentication. So maybe critical viewing, just watching it. That’s the standard approach, right? The critical viewing approach. Or analytics on the, on pixels with quantification of, you know, uh, are there any cut and pastes? Are there any pixel values that jump in ways that they shouldn’t jump? So there’s a lot of algorithms that really focus on, on, uh, the quantification side of, of, uh, of the pixels in the image. People do analysis based purely on audio, right? Audio frequencies, looking for cuts and splices and things like that. So there’s a lot of ways that people approach content authenticity, um, that ultimately all together if used together can create a pretty strong approach. I mean, it takes a lot of knowledge to learn the different techniques and to understand the pros and cons and how to interpret the data, and that’s why there’s not probably a single, uh, tool out there right now because you just have the domain knowledge required is, is quite large. So we’re the kind of tool that we are. Just to tie in where we sit within the question of content credentials in C2PA is that we read, we would be a tool that would ultimately, if we were analyzing it, we would read the C2PA data in your file and say, oh, there’s a C2PA manifest in that file, and we would validate it, and we would then report back, there’s a valid C2PA data manifest, and here’s what the manifest says, so we would also be someone who would play in that ecosystem on the, on the, you know, the side of analysis, not on creation. We don’t create or, you know, get involved with creating C2PA, but we recognize, read and validate C2PA data in a file, for example. Um, we, we’re looking at all the signals, uh, but that would be one signal that we might evaluate, uh, in an authentication exam.
Chris Lacinak: 35:28
You said, uh, Medex won’t tell you if something is real or fake, but just to kind of bring this all together, tying into C2PA, uh, let me say what I think my understanding is, how this might work is, and you correct me when, where I get it wrong. But it seems that C2PA may, for instance, say this thing was created on this camera. It was edited in this software on this date by this person, so on and so forth. Medex can say what created it and whether it’s edited or not. Uh, so for instance, if something, if, if the C2PA data said, uh, this was created in, um, uh, an Adobe product, but Medex purported that it was created in Sora, let’s just say just throwing anything out there, uh, that that it wouldn’t tell you this is real or fake, but it would give you some data points that would help the human kind of interpret and understand what they were looking at and, and make some judgment calls about the veracity of that. Does that sound right?
Bertram Lyons: 36:28
Yeah, that’s right. And I’d say the human and or the, the, uh, the workflow algorithm that’s taking data in and out that, you know, that, from a, think about more like moderation pipeline, you know. C2PA says X, Medex says Y. They conflict, flag it. Or, they don’t conflict, they match. Send it through. You can think about it that way too, from like an automation perspective. Um, but also from a human perspective.
Chris Lacinak: 36:54
For the listeners of this podcast, which are largely DAM practitioners and people leveraging digital asset management and their organizations, I’d love to bring that back up, you know, bring us back up to the level of, of why should a Walt Disney or a Library of Congress or National Geographic or Museum of Modern Art, why should organizations that are practicing digital asset management with collections of digital files, you know, we talked, we kind of delved into like legal things and social media things. But why should an organization that isn’t, uh, involved in a legal dispute or, or, or, or some of the other things we’ve talked about, why should they care about this? And how does, how does content authenticity play into the digital asset management landscape? Can you help us get some insights into that?
Bertram Lyons: 37:37
Yeah, that’s a great question, that’s near and dear to my heart. And we, we probably need hours to talk about all the reasons why, but let’s try to tee up a couple and then you can help me get to it. You know, there’s, I’ll, I’m gonna, I’m gonna list, list a set and then we’ll, we’ll hit some of them. But so, you know, let’s think about collection development, right? So just on the collection development side, we want to know what we have, what we’re collecting, what’s coming in. And we want to apply and we do this as much, as best we can as today, um, in that community with triage tools like, like um, I’ll name one, Siegfried is a good example, built off of the UK’s National Archives PRONOM database. It really focuses on identifying file formats. So, you know, to date, we want to know what file, like as, as, when we’re doing collection development, we want to know what file formats are coming in. Um, but furthermore, actually when we’re doing collection development, you know, I’m speaking of organizations like, like MoMA and Library of Congress, who are collecting organizations. We’re going to get to National Geographic and, uh, Disney and et cetera shortly. You know, on that side, we need collection development tools to make us, make sure we know what we have, right? It goes back to your earlier fakes question. We don’t want to let something in that’s different than what we think it is. And authentication techniques are not present, uh, in those organizations today. It’s a tool that purely metadata, metadata analysis is happening. Just extracting metadata, reviewing the metadata, uh, reviewing the file format based on, based on format, uh, these quote unquote signatures that the UK, Um, National Archives has, has produced and with, with the community over the years, which are great. You know, they’re really good at quickly saying this is a doc, Word doc. This is a PDF. This is a, you know, you know, they identify the type of file. They don’t authenticate the content in any way. So that’s one side of it. Did, um, quality control on big digitization projects is another great way to do this. And start to incorporate this. And of course we kind of do that with metadata techniques still. We’re looking for metadata. We don’t look at file structure, for example, and those kinds of, uh, we don’t know exactly what happened to the file. We know what’s in the file, but we don’t always know what happened to the file. Authentication techniques are focused on that. Um, so I think there’s just ways that that could be added to the current pipelines in those communities. Um, then we think about the file, the content that we’re now storing on the preservation side. We don’t want to necessarily change the hash of files, right? When you’re thinking about libraries and museums and archives. So there’s, there’s probably not a, not a play there to embed C2PA metadata, for example. At least not in the original. There’s probably a play to embed it in the, in the derivatives that are created for access or, or etc. That’s something to discuss. Um, on the create, creation side, you think about companies or organizations like Disney or National Geographic. Content credentials are an excellent mechanism, you know, that and watermarking, which is all, which is all part of the same conversation, um, and moving on, and, and, and this is moving beyond visual watermarking to, uh, non perceptible watermarking, to, to things like that, which are being paired with, with C2PA these days. And, and the, the value there at the, is, is about protecting your assets. Can you ensure that as this asset goes through its lifecycle, whether it’s in your DAM, um, in which case you want your DAM to be C2PA aware or watermark aware. You want your DAM to read these files and report. The C2PA manifest is here for this asset, it’s valid, and here’s the history. You know that that’s another way of securing your assets internally, but then as they go out of the company, whether into advertisements or whether out, you know, being shared to patrons or however they’re being used. out of the company. You know, it’s just another mechanism to ensure your, your copyright’s there to ensure that you are protecting that asset and, and anything that happens to it’s being directed back to you. Um, that’s where on the creative pro, pro production side of the house, that’s these tool sets that are being developed, that are really focused on ensuring content authenticity, they’re, they’re really being built for, for that need. Right? They’re being built for the, for you to have some way to protect your assets as they’re out in the world. That’s why I come back to intent again. Gives you an, a, a, you who have an intent to, to, you know, to do this, the ability to do this.
Chris Lacinak: 42:06
WhAt is the risk? Let’s say that, um, these organizations that, you know, all of which are using digital asset management systems today, choose not to pay attention to content authenticity.
Bertram Lyons: 42:19
It depends on what your company has, you know, what your organization collects and manages, but you know, with these generative AI tools that are out there. Content that makes it out of your company’s hands, if it’s yours and you created it and it has something that has meaning to you, um, it’s very easy for someone to, if you don’t have any protections inside of those files in any way, it’s very easy for someone to, to take that, move it into another scenario and change the interpretation of it and put it back out into the world. This happens all the time, right? So, the, the what, the why there is about protecting, protecting the reputation of your, of your company. That’s a big one. Um, The, the other why is about, I, there’s a, there’s a why that’s not about, you know, the public. It’s the internal why is increased efficiency and, you know, and reducing mistakes. I don’t know how many times we’ve seen, um, companies or organizations that have, uh, mis, misattrib, have misattribution to what’s the original of, of, of an object and what’s the, you know, uh, uh, access copy. And some cases lost the original and are only left with the access copy. And the only way to tell the difference would be some kind of database record, if it exists. If it doesn’t exist, you’d have someone whose experience has to do some kind of one to one comparison. But with the content credentials, um, there would be no, no, no, um, question at all between what’s, what was the original and what was a derivative of that original. From a file management perspective, I think there’s a lot of efficiencies to be gained there. Um, and then, and then, in essence, potentially reducing labor, right? So if, if you think about National Geographic, they have photographers out all over the world doing, you know, all kinds of documentary work. If that documentary work is, from the beginning, has content credential aware tools, there’s, there’s cameras out there, um, etc. Or if those , those photographers are then, or maybe they, maybe it’s not, maybe the content credentials don’t start at the camera, but they start at post process, right, you know, into, into Adobe. I’m not, I don’t work for Adobe, I’m not trying to sell Adobe here, but I’m just using it as an example. But, know, it goes into a product like that, that is, that is C2PA aware, for example. And that photographer can create all of that useful provenance data at that moment, as it makes it to National Geographic, if their dam is C2PA, C2PA aware, imagine all of the reduction in typing and data entry that happens at that point. We trust this data inherently because it was created in this cryptographic way. The DAM just ingests it, creates the records, you know, updates and supplements the records. Um, there’s a lot of opportunity there both for DAM users and for actually DAM providers.
Chris Lacinak: 45:07
Yeah, so to kind of pull it up to the, maybe the most plain language sort of, uh, statements or questions that, that this answers would be again, kind of going back to who created this thing. So a bad actor edits something that’s put out there, posts it, you know, maybe under a, uh, uh, an identity that looks like an entity Walt Disney, for instance, and is trying to say this thing came from Walt Disney. Uh, so this, this sort of suite of tools around content, content authenticity would let us know who actually created that thing and, and allow us to identify that it was not in fact, Walt Disney in that hypothetical. It also sounds like, um, the ability to, um, help identify, you know, something that’s stated as real and authentic, whether it is in fact real and authentic. I’ve got this video, I’ve got this artifact, an image of an artifact. Is this, is this, is this digital object a real thing or not? And vice versa. Someone claiming, and I think we’ll see more and more of this, people claiming that something that is real Is AI generated, right? That’s not real. That’s AI generated. That, doesn’t exist. Uh, the ability to actually, in fact, prove the veracity of something as well, that’s claimed to be non authentic. Um, does that kind of, those three, those are kind of three things that I think what we’ve talked about today points at, like, why would this be important for an organization to be able to answer those questions? And you can imagine in the list of organizations, we, we listed there that there could be a variety of scenarios in which answering those questions would be really critical to their, to those organizations.
Bertram Lyons: 46:51
You give yourself ability to protect yourself and to protect your assets.
Chris Lacinak: 46:56
Right. So, you have really drilled home today the importance of this ecosystem, um, that, that exists and kind of a bunch of people. playing, working, agreeing on, um, building tool sets around, uh, you know, an ecosystem. Are you seeing DAM technology providers opt into that ecosystem yet? Are there digital asset management systems? And I know you don’t know all of them. I’m not saying to give me give us a definitive yes or no across the board. But are you aware of any that are, um, adopting C2PA, implementing Medex Forensics, or similar types of tools into the, into their digital asset management platforms.
Bertram Lyons: 47:43
Not yet, Chris. I haven’t seen a, a DAM company buy into this yet. Um, you know, to be honest, um, I think it’s, this, this is new. This is very much emerging technology. Um, I think a lot of people are waiting to see where it goes and what the adoption is. Um, I will say that two years ago when I started working on, collaborating within the C2PA, uh, schema team, I was, I was feeling like there was very little chance of quick uptake. Um, you know, I, I thought this is a mountain to climb. This is a huge mountain to climb to get technology companies on board, to create C2PA aware technology, whether they have hardware, whether they’re camera, phone companies, whether they’re, whether they’re post processing companies like Adobe, whether they’re browser, you know, serve, like, services, uh, like Chrome, like Google, whether they’re search engines, whether they’re social media. I thought this is just, it’s a, it’s a, mountain. In two years time, however, I don’t know if it was accelerated because of all that’s happened with AI so quickly and the fact that, you know, interests have elevated up to the government level. We have a presidential executive statement on AI, you know, that mentions watermarking. Um, basically mentions C2PA. Um, in two years time, there’s so much change that all of a sudden, um, that mountain feels a lot smaller to climb. It’s like it can be done. Just in the past few months massive organizations have jumped into the Content Authenticity Initiative. Uh, from Intel to NVIDIA, uh, you know, important players in that ecosystem are now coming on board. Um, and I think that, I think that, you know, there’s a chance here. So I, I think we will see DAM folks, uh, who provide systems taking a much stronger look. I will say in the digital evidence management, which we call DEMS, uh, community. there is, there is definite interest in authentic, authentication, right? It’s already happening in the DEMS world, and I think that will bleed over into the DAM world as well. Um, in that content coming into these systems, it’s another signal that the systems can automatically work with to populate and supplement what’s happening behind the scenes. Um, and we, and we know that, that DAMS, DAMS work closely with anything they can to authentic, to, uh, automate, um, their pipelines and make things more efficient for the end user.
Chris Lacinak: 50:18
So I know you’ve done a lot of work. Uh, we’ve talked about today, you know, the kind of law enforcement and legal components of this. Uh, we’ve talked about, uh, digital asset management within, uh, collecting institutions and corporations and things like that. But you’ve done some really fascinating work, I know, with journal within journalism. And within human rights stuff. And I would love, could you just talk a bit about that and maybe tell us some of the use cases that Medex has been used, uh, within those contexts?
Bertram Lyons: 50:52
Think about the context of journalism and, and, you know, human rights organizations is, is really one of, of, of collecting and documenting evidence. Uh, and it may be on the human rights side, a lot of it is collecting evidence of something that’s happened and that evidence is typically going to be video or images. Uh, so we have, we have people documenting atrocities or documenting, you know, any kind of rights issues that are happening and wanting to get that, that documentation out and, and also to have that documentation trusted so it can be believed. So that they can actually serve as evidence of something, whether it’s evidence for popular opinion or evidence for a criminal court, you know, from the UN, both and all, right? So there’s that, that’s the process that has to happen. So there’s, you know, often challenging questions with that kind of evidence, um, to document its authenticity. And in some ways, things like C2PA have come out of that world, you know, there’s an effort with that WITNESS out of New York, um, worked on, and I know they had other partners in it, and I don’t know the names of everybody, so I’ll just say I know it’s not just WITNESS, but I know that they’ve collaborated in efforts for many years to create these camera focused, um, systems that allow that authentic, authent, signal to be stored and processed within the camera upon creation. And then securely share it out from that camera to, you know, to another, another organization or location, um, with all of that authentication data present. And what I mean when I say authentication data there is like hashes and dates and times. Um, and, and, and usually to do it, and the more, the more challenging thing is to do it without putting the name of the person who created the content in the authentication. Because that’s a, that’s a. It’s a dangerous thing for, for some people, for their names to be associated with the evidence of a human, of a human rights atrocity. Um, so they, you know, you think about that’s a really challenging scenario to design for and human rights orgs have been really focused and put a lot of effort into figuring, trying to figure that out. So that you don’t reduce the ability of people to document what’s happened by making it too technologically challenging or costly. Um, and also you don’t want to add harm to that. You want the person who’s, who’s created this to be noted. But then again, at the end of the spectrum, you need to trust it. You need someone else to trust it. But you can’t say who did it, you can’t say anything, you know, right? So, so there’s been a lot of excellent work. And I know we’ve been involved a lot on the side of, of helping to provide input into authentication of, of video from, from these kinds of scenarios. Um, to add weight to trust, right? Ultimately, it’s all around trust. Can we trust it? Uh, what signals do we have that allow us to trust it? And do they outcompete any signals that would want us to distrust it? Um, so that’s, that’s been really exciting. That work, you know, is, is continually going on. And I know there’s a lot of organizations involved, but we’ve partnered closely with WITNESS over the years and they, they do excellent work. Um, and I know that there, there’s a lot more out there, but you know, that’s, On the journalism side, it’s a little different than that, right? On the journalism side, you have, uh, journalists who are writing investigative reports, right? And their job is to, in a little bit of a different way, is to receive or acquire, um, documentation that’s of world events or local events, um, and to quickly attain or assess the veracity of that content so they can make the correct interpretation of it. And also decide the risk of actually using it as evidence in a piece, in an article. Um, we work closely with a variety of organizations. The New York Times is a good example of, of a group we work closely with where, you know, it’s not always easy. You know, even if you’re receiving from a particular human being on, you know, in some location, you’re receiving evidence from them, you know, you want to you want to evaluate it with as many tools as you can. You want to watch it. You want to look at its metadata. You want to look at its, uh, authentication signals. And you want to ultimately make a decision on, can we write, are we going to put this as the key piece of evidence in an article? It’s never first person, right, from the journalist’s perspective. They’re not the first person usually, right? So they’re, they’re having to take this as, uh, from someone who delivered it to him, who is also, they can’t prove is first person. You know, they have to decide how first person is the content in this, in this video or image or, or audio. So, um, I don’t know if that answers your question, but that’s, you know, we, you see a lot of need for the question of content authenticity in both of those worlds. And, and a lot of focus on it.
Chris Lacinak: 55:53
Yeah. So, well, maybe just to pull it up to a hypothetical or, or even hinting at real world example here, like, uh, let’s say a journalist might get a piece of video, um, out of, let’s say Ukraine or Russia, uh, and they’re reporting on, on that war. And, and, uh, they have gotten that video, let’s say, through Telegram or something like that. Uh, so, their ability to make some, uh, calls about the veracity of it are really critically important. And I, they could use Medex and other tools to say, for instance, that, yes, this came, you know, if it looks like it’s cell phone footage, that, yes, this came, this was recorded on a cell phone. Uh, uh, yes, this came through Telegram. Um, no, it was not edited, no, it did, it was not created through an AI generation tool or a deep fake, uh, piece of software, things like that. That would not tell them yes or no, they definitively can or can’t trust it, but give them several data points that would be useful for making a judgment call together with other information on whether they can trust that and use it as, as journalism. Uh, in their journalism.
Bertram Lyons: 57:04
That’s right. Yeah, it’s always the human. At the end, and I’ve stressed this, uh, as much as I like automated tools, we really need, in scenarios like that, a human to say, this is my interpretation of this, all of these data points that I’m seeing. Um, and, and that’s a great example. And that’s a real example. We actually dealt with it. Remember when the nuclear, um, when that war just originally broke out, there was challenges to, um, nuclear facility there. There were, um, it was still under the control of Ukraine and there were Ukraine scientists in the facility sending out Telegram videos saying we’re here, there’s bombing happening around this nuclear facility, this is extremely dangerous, please stop. Um, and, and the video was coming out from Telegram. But the only, the only way to evaluate it was, was from a secondary encoded version of a file that, you know, Um, initiated somewhere, uh, and then it was passed through Telegram to a Telegram channel and then extracted by news agencies and then they want to, um, as quickly as possible say is this real? We want to report on this. We want to amplify this, um, this information coming out from Ukraine. It’s challenging, you know, in that case, you know, we, we, in the case of, in the files that we were asked to evaluate in that case, you know, we could say, yeah, you know, it was. It’s encoded by Telegram, um, and, and it was, you know, it has, it has some signals left over that we’re able to ascertain that, that, that would only be there if this thing originated on a cell phone device, on a Samsung, for example. Um, so there’s the census, maybe that’s all the signal you have, and you have to make a judgment call at that point. point Um, now. In the future, what if Telegram embedded C2PA data, you know, and, and that, and that was still there and we could, you know, maybe that’s a stronger signal at that point.
Chris Lacinak: 59:00
Yeah. Or combined. It’s another data point, right?
Bertram Lyons: 59:08
Yeah, it’s just another data point, right?
Chris Lacinak: 59:09
Great. Well, Bert, I want to thank you so much for your time today. Uh, in closing, I’m going to ask you a totally different question, uh, that I’m going to ask of all of our guests on the DAM Right Podcast, which Uh, help shed a little light, I think, into the folks we’re talking to. Get out of the weeds of the technology and, and, and details. And, and that question is what’s, what’s the last song you liked or added to your favorites playlist?
Bertram Lyons: 59:33
The last song That I added to my like songs was Best of My Love by The Emotions
Chris Lacinak: 59:43
That’s great. Love it.
Bertram Lyons: 59:46
Ha ha ha ha You know, I mean, actually I’ve probably added that like 3 or 4 times over the years It’s probably on there, different versions of it Um, that’s great, great track, I used to have 45 of it. You know that track.
Chris Lacinak: 59:59
Yep. It’s a good one.
Bertram Lyons: 60:00
I recommend you play it as the outro from today’s DAM
Chris Lacinak: 60:03
If I had the licensing fees to pay, I would. Alright, Well, Bert, thank you so much for all of the great insight and, and, and contributions you made today. I really appreciate it. And, uh, it’s been a pleasure having you on the podcast.
Bertram Lyons: 60:17
Thanks for having me, Chris.
Chris Lacinak: 60:18
Thanks for listening to the DAM Right podcast. If you have ideas on topics you want to hear about people, you’d like to hear interviewed or events that you’d like to see covered, drop us a line at [email protected] and let us know. We would love your feedback. Speaking of feedback. Please give us a rating on your platform of choice. And while you’re at it, make sure to follow or subscribe so you don’t miss an episode. If you’re listening to the audio version of this, you can find the video version on YouTube using at @DAMRightPodcast and Aviary at damright.aviaryplatform.com. You can also stay up to date with me and the DAM Right podcast by following me on LinkedIn at linkedin.com/in/clacinak. And finally, go and find some really amazing and free DAM resources from the best DAM consultants in the business at weareavp.com/free-resources. You’ll find things like our DAM Strategy Canvas, DAM Health Scorecard, and the “Get Your DAM Budget” slide deck template. Each resource has a free accompanying guide to help you put it to use. So go and get them now.
Insights from the Henry Stewart DAM LA Conference 2024
28 March 2024
The Henry Stewart DAM LA conference brings together industry professionals to discuss the latest trends, challenges, and innovations in Digital Asset Management (DAM). This year’s conference showcased a vibrant atmosphere filled with networking opportunities, insightful presentations, and engaging discussions. Here’s a look at the key themes and takeaways from the event.
Day One Highlights: The Buzz of Excitement
As the conference kicked off, there was an unmistakable buzz in the air. Attendees from around the world were ready to dive into the rich content and networking opportunities that the conference offered.
Emerging Themes and Trends
Christine Le Couilliard from Henry Stewart shared insights about the evolving landscape of DAM. She noted a significant focus on global expansion, with DAM serving as a catalyst for growth within organizations. The personalization of content outreach was highlighted as a key agenda item, alongside the rise of AI and generative AI technologies.
Attendees expressed a keen interest in how DAM systems can facilitate not just content management but also strategic planning across larger enterprises. This focus on enterprise-wide integration reflects a growing recognition of DAM’s central role in organizational success.
Voices from the Floor: Attendee Insights
The conference featured a variety of perspectives from attendees. Here’s what some of them had to say about their expectations and excitement for the sessions ahead.
Amy Rudersdorf’s Insights
Amy Rudersdorf, Director of Consulting Operations at AP, shared her enthusiasm for learning how major brands are managing licensed content efficiently. She emphasized the importance of automating rights management to streamline operations and reduce the reliance on manual processes.
Matt Kuruvilla on Rights Management
Matt Kuruvilla from FADEL expressed excitement about the ongoing discussions surrounding licensed content and how brands handle rights management. He highlighted that the growing complexity of content creation necessitates effective automation solutions.
Yonah Levenson’s Perspective
Yonah Levenson, co-academic director of the Rutgers DAM Certificate Program, reflected on the evolution of DAM discussions over the years. He noted that early conversations revolved around basic concepts, while current dialogues focus on integration with other systems and the advanced capabilities of DAM platforms.
New Innovations in AI and Automation
AI and automation were hot topics, with many participants eager to explore how these technologies can enhance DAM workflows. The potential for AI to expedite tagging processes and improve metadata management was a particular area of interest.
Nina Damavandi on AI Applications
Nina Damavandi from USC shared her excitement about leveraging AI and machine learning to expedite tagging processes, a challenge that many organizations face. She highlighted the need for efficient data management to enhance asset utilization.
Leslie Eames on Automation
Leslie Eames from the Maryland Center for History and Culture discussed her interest in automating metadata processes. She emphasized the importance of ethical considerations in using AI tools to ensure equitable benefits from shared data.
Networking and Community Building
Networking opportunities were abundant, with attendees sharing stories, challenges, and successes. The conference fostered a sense of community, reminding participants that they are not alone in their struggles.
Billy Hinshaw on the Value of Networking
Billy Hinshaw from Bissell Homecare emphasized the value of meeting peers and hearing their stories. He noted that these connections are crucial for professional growth and learning from one another’s experiences.
Key Takeaways from Day Two
As the conference progressed into its second day, several themes emerged that encapsulated the evolving nature of DAM.
The DAM Ecosystem
Emily Somach from National Geographic highlighted that DAM systems are central to a broader ecosystem. She stressed the need for seamless integration with various other systems used within organizations, ensuring that all components work harmoniously together.
Christina Aguilera on Community and Collaboration
Christina Aguilera, Vice President of Product for Crunchyroll, shared her multifaceted career journey and the importance of community in professional development. She underscored how the relationships formed at conferences like Henry Stewart can open doors to new opportunities.
Technology Providers’ Perspectives
The conference also featured insights from various DAM platform providers. Each shared their unique offerings and how they differentiate themselves in a competitive landscape.
Orange Logic’s Cortex Platform
Christopher Morgan-Wilson from Orange Logic introduced Cortex, an enterprise-level asset management software that adapts to user needs. He explained how this flexibility allows organizations to consolidate multiple DAM solutions into a single source of truth.
FADEL’s Innovative Solutions
Matt Kuruvilla highlighted FADEL’s focus on automating content rights management, emphasizing the necessity for brands to manage licensed content efficiently.
Bynder’s Usability Focus
Brian Kavanaugh from Bynder discussed the platform’s emphasis on usability and configurability, ensuring that organizations can maximize their DAM investments.
Looking Ahead: The Future of DAM
As the conference drew to a close, discussions turned to the future of DAM. The concept of DAM 5.0 was debated, with attendees speculating on how the landscape might evolve.
AI’s Role in the Future
Participants expressed varying opinions on the role of AI in DAM. While many were optimistic about its potential, there were also concerns about the limitations of current technologies, particularly in terms of metadata entry and contextual understanding.
Content Authenticity and Security Concerns
One topic that received less attention than anticipated was content authenticity. With the rise of generative AI and deep fakes, the need for robust security measures is becoming increasingly critical.
Final Thoughts
The Henry Stewart DAM LA conference not only provided valuable insights into current trends but also fostered a sense of community among professionals in the field. As the industry continues to evolve, the conversations sparked at this event will undoubtedly shape the future of DAM.
For those looking to stay updated on the latest in DAM, it’s essential to engage with this community and share experiences, challenges, and solutions. The power of collaboration and knowledge sharing is the key to navigating the complexities of digital asset management.
Thank you for joining us in this recap of the Henry Stewart DAM LA conference. We look forward to seeing how these discussions will influence the future of DAM in the coming years.
Transcript
CHRIS LACINAK
So here I am at home about to leave for Henry Stewart DAM LA. I’m excited although there’s two to three feet of snow on the ground here. I have to say it’s a gorgeous day and I wouldn’t otherwise want to leave but for Henry Stewart DAM LA I’m down. Let’s go. Henry Stewart DAM LA here comes the AVP and the DAM Right Podcast.
[Music]
All right here we are day one of the Henry Stewart conference. Let’s go in and let’s talk to some people. I’m here with Christine Le Couillard from Henry Stewart. Christine how’s the conference going so far?CHRISTINE LE COUILLIARD: 01:15
Oh Chris it’s great. There’s a real buzz, a real buzz about the place. We’ve seen folks coming from all over, not just the US but overseas and they’re just hungry for content, hungry for networking, hungry to see what’s next on the agenda.CHRIS LACINAK: 01:33
Yeah and you’ve got such unique insights because you help put the program together for Henry Stewart every year. So are there topics or themes that you think are emerging this year that are new?CHRISTINE LE COUILLIARD: 01:42
Great question. I think we’re looking at global expansion. How DAM is that helpful catalyst within an organization to help companies grow and expand and with a whole personalization of content, outreach and so on. That is certainly high up on the agenda. Connected to that is AI, generative AI. Where’s that leading? It’s scary but there’s an opportunity there too to make it work for you.CHRIS LACINAK: 02:13
I’m here with Amy Rudersdorf, Director of Consulting Operations at AVP and we’re starting the day, day one of the Henry Stewart DAM LA Conference and Amy, love to hear what what are you excited to hear about at this conference?AMY RUDERSDORF: 02:27
I’m really excited to see what the Maple Leafs are doing with their DAM. They are talking about moving from implementation and moving a million objects into their DAM in a short period of time and then bringing their strategic plan to the larger organization. So bringing it enterprise-wide all while the Maple Leafs are playing and they’re adding new assets all the time. So it’ll be exciting to see what they’re doing.CHRIS LACINAK: 02:56
I’m here with Matt Kuruvilla from FADEL. Matt, what are you most excited about hearing about at this conference this year?MATT KURUVILLA: 03:03
Well, I’m tempted to say spending time with you, Chris, because this has already been so much fun. But I am really excited to see how brands are handling all their licensed content and managing those rights and making sure that’s easy and automating that because I just feel like that’s a bigger part of how content’s being made nowadays. So you got to have a way to solve it that doesn’t require a whole lot of humans. So I’m excited to hear how people are doing that today.CHRIS LACINAK: 03:28
I’m here with Yonah Levenson. Yonah, can you tell us a little about who you are first?YONAH LEVENSON: 03:32
Sure, I am the Co-Academic Director of the Rutgers DAM Certificate Program, State University of New Jersey, and along with David Lipsey is the other Co-Academic Director. And I’m also a metadata and taxonomy strategy consultant.CHRIS LACINAK: 03:48
Great, great. And you’ve been coming to Henry Stewart for a long time now.YONAH LEVENSON: 03:53
This is true.CHRIS LACINAK: 03:54
What would you say, what are you seeing as some of the themes or trends over these years and kind of where we are today?YONAH LEVENSON: 04:01
So way back when at the beginning it was what’s a DAM? And then it was how do I update my DAM? And then it was how do I replace my DAM? And then it’s become how do I integrate my DAM with other systems? And now it’s how do I get my DAM not just to integrate with other systems but also to push the envelope and how much can I do within and across my DAM? And there’s also been I think a much bigger interest in metadata and taxonomy because it’s being recognized that you have to have a way to have commonalities and normalize language across multiple systems if you’re going to do it right. So that this way when senior management says, “Hey, can you get me a report on this?” You’re not going to like necessarily 15 different places and then having to figure out does this really mean that?CHRIS LACINAK: 04:57
Right, right. Okay, great. Well, thank you for that insight. I appreciate it.YONAH LEVENSON: 05:01
You’re welcome.CHRIS LACINAK: 05:02
All right, I’m here with Phil Seibel from Aldis. Phil, what are you most excited about at this conference this year?PHIL SEIBEL: 05:08
Yeah, honestly I’m just really excited to see what people are doing, what’s new in the industry, how things are trending. It always feels like at this conference that people are both looking to share everything they’ve learned and find new things and it’s really interesting to see where people have made up ground and where they’re still looking to make up ground in the industry and I really like to feel the pulse of things here so that’s what I’m looking forward to.CHRIS LACINAK: 05:29
Awesome, all right, here to feel the pulse. Sounds good. Thank you, Phil.
I’m here with Nina Damavandi from USC, Digital Asset Manager. And Nina, I’d love to hear what are you most excited about, any particular topics or sessions or anything at the conference this year?NINA DAMAVANDI: 05:43
Yeah, I think the main thing I’m excited about is how companies are using AI and machine learning in their DAM workflows to expedite the tagging process. That’s kind of one of our biggest struggles at USC is getting enough data on our assets and so if there is a way to make that faster and I look at our assets they share so much in common like there should be a way to make this easier without so much human labor needed.CHRIS LACINAK: 06:09
Yeah, and we’re about halfway through the first day so have you gotten any nuggets yet?NINA DAMAVANDI: 06:15
Yeah, there were a couple of good sessions this morning on the topic of AI like Netflix gave a great presentation so I think they are much further ahead with it than we are but it’s really cool to see what the potential is.CHRIS LACINAK: 06:27
All right, I’m here with Billy Hinshaw, BISSELL Homecare. Billy, what are you most excited about at the conference this year?BILLY HINSHAW: 06:32
Just the continuing networking opportunities, meeting so many people, hearing their stories, hearing about what they do and seeing where there’s similarities in terms of the accomplishments and the struggles that they deal with. I think the biggest benefit of attending these conferences is that we realize we’re not alone. We might be on an island, you know, at our particular companies but that’s not the reality as far as our industry is concerned nor should it ever be.CHRIS LACINAK: 06:59
Yeah, well that’s that’s fantastic summary of the value of Henry Stewart for sure. Now you’re a past presenter at Henry Stewart and you’re presenting this year, popular sessions. Can you tell us a little bit about what you’re presenting on tomorrow?BILLY HINSHAW: 07:11
I’m presenting on the different responsibilities that DAM professionals have to balance and how to best manage that without losing losing your mind basically. Yeah, that’s important to keep your mind intact.CHRIS LACINAK: 07:26
Awesome, well thank you Billy, I appreciate it.BILLY HINSHAW: 07:28
Yep, thank you Chris.CHRIS LACINAK: 07:29
I’m here with Leslie Eames. Leslie, can you tell us who you are?LESLIE EAMES: 07:33
Yeah, I’m Leslie. I’m the Director of Digital Collections and Initiatives at the Maryland Center for History and Culture.CHRIS LACINAK: 07:38
Great, and is there any particular topics or sessions or anything that you’re most excited about this year at the conference?LESLIE EAMES: 07:45
Yes, I’m really looking for ways to automate our metadata processes so we can ingest more of our data into our DAM. So looking at machine learning and AI tools that can help us and then also exploring some of the ethical implications behind those, knowing that, you know, we want to be deliberate about who’s benefiting from the data we’re sharing when we use those tools.CHRIS LACINAK: 08:11
Yeah, the ethics part of that is a very important part of that conversation. That makes sense. We’re about halfway through the first day so far, so have you have you gotten what you’re looking for yet or are you hopeful to find it in the coming day and a half?LESLIE EAMES: 08:25
I feel like it’s coming together slowly. I’m getting pieces here and there from a lot of different sources, so I’ve learned a lot and hoping to learn more and make connections with others that continue to grow my knowledge.CHRIS LACINAK: 08:39
All right, so I’m here with Emily Somach from National Geographic. Emily, thanks for talking to me. I appreciate it. So we’re nearing the end of the conference on day two. Are there any particular themes or takeaways that you found interesting this year?EMILY SOMACH: 08:53
Yeah, definitely. I think the biggest takeaway and theme too is that the DAMs is really at the center of an ecosystem. We all have other systems that are integrating with it and communicating with it and just always keeping that in mind when you’re working in the DAMs or changing things in the DAMs or building a DAMs. Just knowing that eventually it’s going to be connecting and talking to all these other systems that either you or your coworkers or other teams in your organization are using. So I think that’s just an important thing to keep in mind. And then I guess some other, I guess, yeah, always thinking about the next step and the future and what you can do to set yourself up for success. Migration is just a big part of our world, so always knowing that you might be having to migrate down the road or bringing stuff in from another system eventually and kind of keeping that in mind and making sure everything works together and is standardized.CHRISTINA AGUILERA: 09:43
I am Christina Aguilera and I have multiple jobs. So we’ll start off with my most recent. So I am currently, I just joined Crunchyroll. So I’m the Vice President of Product for Enterprise Technology and Enterprise Technology to Crunchyroll is basically the entire studio workflow. So it is amazing the way that we incorporate asset management into the operations of getting content published to a platform. So that’s an incredible opportunity. I’m also the president of Women in Technology Hollywood Foundation. So as part of Women in Technology Hollywood Foundation, that is my nonprofit where I get to spend all my passion. So we do a lot of professional development opportunities. We’ve got mentorship programs. We do live events in the spring and the fall. The spring is technology focused, the fall is leadership focused. So it’s a great combination and a great network. And then also I am launching a new business with some incredible women out there. So in March on International Women’s Day we launched the brand and it’s called Enough. And it’s basically we are going out there to all of those women leaders globally and making sure they know they are enough. So this is a professional development platform as well as a community and that platform launches April 17th. So that is our brand reveal, our brand launch that’s happening in April. And it’s really really exciting. I think it’s going to change the world.CHRIS LACINAK: 11:11
Wow.CHRISTINA AGUILERA: 11:12
Yeah.CHRIS LACINAK: 11:12
Wow. Wow. So you’re a powerhouse.CHRISTINA AGUILERA: 11:14
I love it.CHRIS LACINAK: 11:15
You’re doing all kinds of things. That’s amazing.CHRISTINA AGUILERA: 11:17
I’m about this close to publishing a book too.CHRIS LACINAK: 11:19
Fantastic. That’s amazing. You’ll have to tell us how you do all these things at some point.CHRISTINA AGUILERA: 11:23
Very little sleep.CHRIS LACINAK: 11:24
And what so what do you think the value of coming to the Henry Stewart Conference is?CHRISTINA AGUILERA: 11:29
You know I’ve been involved with the Henry Stewart Conference for probably over 20 years now. I’ve known them throughout my entire career and the biggest value to me is the people and the people you meet and the people that you grow to connect with and you build the relationships with. You don’t know when you’re first meeting somebody if they’re gonna open that future door for you.CHRIS LACINAK: 11:55
Yeah.CHRISTINA AGUILERA: 11:55
So my career has taken so many different paths and the people that I’ve met at Henry Stewart have opened many of those doors. So it’s an incredible community of people. It’s a great place to come and connect on like ideas and like concepts and it doesn’t matter what industry we’re in or what our job title is because we all have similar problems in the workplace and we come here to commiserate and build relationships and help each other evolve in our careers.CHRIS LACINAK: 12:24
Thanks for listening to the DAM Right podcast. If you have people you want to hear from, topics you’d like to see us talk about, or events you want to see us cover, please send us an email at [email protected]. That’s [email protected]. Speaking of feedback, please go to your platform of choice and give us a rating. We would absolutely appreciate it. While you’re at it, go ahead and follow or subscribe to make sure you don’t miss an episode. You can also stay up to date with me and the DAM Right podcast by following me on LinkedIn at linkedin.com/in/clacinak. And finally, go and find some really amazing and free resources focused just on DAM at weareavp.com/free-resources. That’s weareavp.com/free-resources. You’ll find things there like our DAM Strategy Canvas, our DAM Health Score Card, and the Get Your DAM Budget slide deck template. Each one of those also has a free accompanying guide to help you put it to use. So go get them now.
Let’s turn to the DAM platforms in the room now. I’m gonna ask them each a series of questions and I’m gonna edit it so that you can hear their answers side by side. Before we get into the questions, I’ll introduce you to each of them. Christopher Morgan-Wilson from Orange Logic. Shannon DeLoach from Censhare. Melanie Chalupa from Frontify. John Bateman from Tenovus. Brian Kavanaugh from Bynder. Bróna O’Connor from MediaValet. Jake Athey from Acquia. Tell us about your platform and what differentiates you from the other platforms in the room today.CHRISTOPHER MORGAN-WILSON: 14:01
Orange Logic has created Cortex. Cortex is an enterprise-level asset management software that’s actually able to adapt the way it presents itself depending on the user. So if you think a lot of companies out there, they’ll buy multiple DAM solutions. Like their teams and departments will kind of go rogue and buy different software. But now there’s a big push for companies to consolidate all that into one central source of truth and that’s where Orange Logic comes in with Cortex.SHANNON DELOACH: 14:28
Censhare is an omni-channel DAM, PIM, and CMS platform. What differentiates us is it’s fully integrated out of the box. So there’s no outside integrations needed to get that full functionality. Those three functionalities, DAM, PIM, and CMS, are built on a common structure. So it’s very flexible. Really where we stand out is if you need DAM and PIM, our niche is where you can buy one platform and have them both. So that’s what we’re very proud of.MELANIE CHALUPA: 14:57
Frontify is a brand-centered solution that’s focused on all facets of your brand. So of course looking at a critical element of your brand is going to be the DAM itself, but on top of that we also have the ability to digitize all of your guidelines. And a lot of our clients will also include a multi-portal setup. So looking at your corporate brand, the assets that are associated with that, as well as the guidelines, sometimes campaign toolkits, but also being able to support product brands, employer brand, really every facet of your brand. So that’s kind of our unique differentiator.JOHN BATEMAN: 15:24
Tenovos is about a five-year-old company, so relatively young in the company of a lot of legacy DAM providers. So we like to think that we’re differentiated because of the architecture of our platform built on microservices, APIs, and very flexible modern technology, very scalable. So that sets us apart. It really means that we can fit in into different ecosystems in people’s MarTech stacks. So very easy to connect with other platforms, other technologies. So I think that’s one of the key differentiators.BRIAN KAVANAUGH: 16:11
Bynder is a leading digital asset management platform according to Forrester, as well as our G2 customer reviews. And I would say what sets us apart is first and foremost use cases in the enterprise, but when you look at Bynder, it’s really usability and configurability of the platform, the most integrations, and the biggest marketplace in terms of plugging into other platforms, and then a leading AI strategy centered around search as well as generative AI. So those are three things that come to mind, Chris, but there’s certainly more as well.BRÓNA O’CONNOR: 16:40
MediaValet is a Canadian DAM. We are a digital asset management vendor. We are built on Microsoft Azure, so we are the only platform built exclusively on Microsoft Azure. We help customers across a variety of industries, so whether they are higher ed, non-profit, manufacturing, media and entertainment of all sizes, from SMB through to enterprise, and we work with those organizations to deliver content at scale. So very much a core DAM platform that delivers seamlessly through integration so that your users can work in the systems that they love, but have a great DAM platform at its base. And in terms of setting us aside, I think we’re very proudly rated the highest security vendor for DAM, so the highest security rating, we’ve got a 99% rating there, so we’re exclusively a league of our own in that area.JAKE ATHEY: 17:28
Acquia is the open digital experience platform, and we provide content management, digital asset management, product information management, and customer data management solutions, and Acquia acquired Widen in 2021, which is where I come from as one of the early pioneers in the DAM space, and I’ve been in this space for 20 years. Let’s focus on some of our strengths. Our strengths in flexibility and adaptability, really leaning into that open promise of Acquia, and the fact that we integrate with anything, and that’s really key among our roadmap priorities as well, and then having a scalable performance and governance model, and being one of the few combined DAM and PIM platforms on the market.CHRIS LACINAK: 18:12
For this next question, taking AI off the table, what in your roadmap is your company most focused on or most excited about?CHRISTOPHER MORGAN-WILSON: 18:20
Orange Logic. One of the big things right now is different file formats. Last year was a huge push for MAM, so media asset management, or I guess multimedia asset management, so video. We’re seeing a lot of requests for working with 3D files, project files, resource management, so like not only being able to handle the assets, but the people working on those assets, their time, the budget. Again, it’s that central source of truth where everything regarding the asset, from ideation to creation, all the way to final approval, like pushing out to other platforms, all that is handled within the DAM.SHANNON DELOACH: 18:55
Censhare. We’re most focused on our cloud initiative, right? So we’re going cloud native. It’s going to offer much more flexibility and faster speed to deployment for our customers. So that’s really the aim, to get our customers a usable system more quickly. We’re going cloud native.MELANIE CHALUPA: 19:13
Frontify. So something we’ve been focused a lot on lately is templates. So we do have a template offering within our portal, or our brand portal solution, is of course templating and being able to scale production across several channels is such a critical part of leveraging and getting the most out of your assets, but also being brand compliant. So something that we’re looking to do right now is to further enhance that tool and be able to include things like video templates and being able to manipulate templates for each channel in one go. So I think that’s something that has been really resonating with our clients and we’re looking forward to offering more in that realm.JOHN BATEMAN: 19:46
Tenovos. When the company set about developing a DAM platform, in the back of our minds was how can people get value from the assets and how do you derive the most value? Previously you couldn’t really see how things were performing out in the wild once it left the DAM. So our ideas really from the start, I think from the inception of Tenovos, have been around that smarter use of the assets and smarter use of your resources being guided by the data that you’re pulling back from the assets through all your different channels, whether it’s your social, through your e-commerce, etc. So I think that for us it’s a big focus at the moment.BRIAN KAVANAUGH: 20:36
Bynder. Composable architecture and just using a best-in-breed approach for sure.CHRIS LACINAK: 20:42
Okay, that’s a lot of big words. Can you break that down for us a little bit?BRIAN KAVANAUGH: 20:47
What we’re most excited about is organizations taking what we call a best-in-breed approach to their MarTech stack, not being dependent on a single suite provider or single platform. More identifying needs and capabilities for DAM but also adjacent technologies around CMS, marketing automation, what-have-you, and using the best vendor for each and integrating their platforms using APIs. And another big theme that is right tied into that is delivery of assets. So being more intelligent, more automated, more sophisticated of how assets get delivered out of the DAM to downstream platforms that the customer touches.BRÓNA O’CONNOR: 21:24
MediaValet. We’ve got an exciting roadmap ahead of us this year which we are finalizing and building at the different components but something that’s coming up very soon that I think you’re going to hear from us is about templating. So we’re working with a great partner called Mark and we will be releasing a templating solution in Q2 which will really enable our marketing customers to really drive better impact by enabling their teams to work efficiently with their campaign materials, drive more campaigns out the door, and then leverage your other resources on more strategic initiatives. So it’s really empowering your team to do more which of the time we’re in that is really important for our marketing organizations to drive that efficiency.JAKE ATHEY: 22:03
Acquia. Top non-AI priorities of 2024. We have the priority of integrated workflows. We want more native integrations and more partnerships to really help our customers optimize their content operations as well as to connect assets and metadata across the digital experience. We also have new insights analytics and reporting capabilities with new data visualizations and more analytics API endpoints coming so that customers can work with their DAM data, their DAM reports within whatever business analytics tools that they use. And we also have a new search experience coming with enhanced usability, accessibility, and some added features. And of course we’re advancing our PIM and DAM combination with added PIM and added syndication capabilities that we’re very excited about for our customers that are makers and marketers of products.CHRIS LACINAK: 22:57
Putting AI back on the table, which of the following are you most focused on in the application of AI? Content generation, search, or tagging and description?CHRISTOPHER MORGAN-WILSON: 23:07
Orange Logic. So it’s a good mix of everything. Right from the get-go we’ve always focused heavily on the search because there’s really no point in having a DAM if people can’t find what you’re looking for. And I used to be an asset manager on Disney’s AFV for about seven years so I was the one doing the tagging and it’s so hard to know what people are gonna search for. So if you use the AI for the tagging and the searching that kind of gives you a level up on you know surfacing those assets. And then the third one we are now starting to focus on content generation whether that’s actual physical images based off of other assets in your DAM, document creation like being able to create a brief before you kick off that project. So you’ve cheated and said all three I asked you to pick one. Oh I’m sorry. That’s okay that’s fine. I think we’ll assume that. Searching is the most important. Search, okay all right fair enough.SHANNON DELOACH: 23:57
Censhare. Oh content generation for sure. Okay and can you tell us at all about where how you’re focused on content generation? Yeah so generative AI right so creating product descriptions right so you have a great product and you want to quickly create those descriptions we want to generate that for you. Generating images even videos the whole concept of you know create once use many but now let’s just do it with AI so you can do it faster. And actually using AI to find specific areas within content that you may want to reuse. So I said a mouthful there but really it’s really it’s a lot of our clients are using it for yeah creating those those quick you know give me three bullets on my new product right so boom we can generate it now that’s in the DAM now you can use that and push that out to you know your online channel or whatever other platform or whatever, so.MELANIE CHALUPA: 24:54
Frontify. Probably search at the moment so we’ve recently rolled out our brand AI assistant so that’s going to be able to help our clients have their end users enter their portal and search for assets and through their guidelines and kind of chat to this bot to be able to find what they need and also have that bot generate answers for them that might not even involve them going into the system further so really looking at improving that kind of speed to search timeline as well. We do have some other exciting things around the other elements that you mentioned. Okay tell us tell us about it. Okay yeah so we’re also rolling out a plug-in with open AI where you can generate images within the DAM so on that kind of generative image topic that’s what we’re doing there and we already have AI tagging which has been really great and helping our clients to cast that wide net so that whatever their end-user search for has you know the most likely hood of producing results for them.JOHN BATEMAN: 25:43
Tenovos. Content creation I think and you know really you know the generative stuff is very interesting at the moment but things like localization of assets is it seems to be very prevalent on some of the big global brands that we’re we’re working with that’s a big thing at the moment and then things like you know some of the the cropping and creating different derivatives of assets for different different formats and that sort of thing so yeah I’d say probably the latter two you know search and tagging I think we feel have been done you know for a number of years and work you know it’s kind of matured but I think the content creation side of us seems to be evolving at a sort of exciting pace now particularly around the generative stuff you know.BRIAN KAVANAUGH: 26:35
Bynder. So I think when it comes to tangible applications and what our customers are getting ROI out of like every single day and discovering new use cases for I would start with search because it’s this whole philosophy of a great place to start with AI in your organization is maximizing existing data and what is existing data for a DAM? Well it’s usually the volume of assets you’ve built up over time where if you can apply AI to it there’s just a added level of discoverability and an added level of efficiency you’re going to get which every organization right now is focused on when it comes to efficiency or getting more out of what they’ve already created. So I know generative is exciting and I know that there’s probably a lot to unlock from here on out but if I think of the here and now, it’s really search I think represents the most efficiency.BRÓNA O’CONNOR: 27:23
MediaValet. I would say you’re gonna hear more from us on search very soon with us developing that area. Tagging is a huge one, especially for our customers that have huge libraries, right? So they’re ingesting a ton of content into the DAM and that automatic tagging with AI has been essential for them to get through utilizing their catalogs. Something related to that that we’re very excited about and I was speaking with our customer here about is the Jane Goodall Institute leverage video intelligence. So that’s another AI capability that they’re leveraging and really it’s about extracting that content from their video and then for reuse. So leveraging content, using AI to generate transcripts and social quotes and everything has been really important for that customer and a great story we talked about yesterday as Henry Stewart DAM LA.JAKE ATHEY: 28:07
Acquia. I want to say all three because we have all three among our roadmap priorities for the next year: smart tags is one of those roadmap priorities, smart tagging and search. Effectively, search is the desired outcome. We also have this concept of automatic video transcription and automatic video generation and templates, and so we are excited about the generation capabilities there. But I’m gonna go search if I have to pick just one because that’s really fundamental to DAM. Should I say funDAMmental is if I will, yeah.CHRIS LACINAK: 28:41
Got to get the DAM pun in.JAKE ATHEY: 28:43
Indeed, never gets old.CHRIS LACINAK: 28:44
Now there’s a few providers in the room that are not DAM platforms. They’re add-ons, they’re partners, they’re technologies that work alongside DAM, and I’d like to ask them some questions. They’re a bit different, so I’m gonna approach this one a little bit differently and just talk to each one for a few minutes. Reinhard Holzner from Smint.io, we see that you are not a DAM, so can you tell us what you are?REINHARD HOLZNER: 29:11
Hey Chris, yeah, so we are not a DAM but we work with your DAM. Imagine you have your favorite DAM and you want to give it different experiences for different audiences. We say the DAM is not the right place for everybody to for every audience, for example. So if you want to reach other audiences like partners or the press or your employees, you might need a different experience, and that’s what we do with our content portals. You can build a brand portal, you can build a media center, you can build a download area, you can build all those different experiences on top of your DAM that you can’t do with your DAM alone.CHRIS LACINAK: 29:47
Could you give us an example of a, I mean I don’t know if you’re allowed to use client names or not, but maybe not, if you can just anonymize it, give us an example of how one of your clients uses Smint?REINHARD HOLZNER: 29:56
So we have several clients that we can name, for example, we have in Europe we have Ferrero Group, which is one of the largest retailers in Europe. They use this, for example, for the internal product portal or product imagery portal, so all the employees can access the imagery that is required through easy to use, simple, mobile-enabled interface and they don’t need to go to the DAM, which is very complicated, for example. Or we have two of the largest sports organizations in the world as our clients where I cannot name them, but I can tell the story. So they reach the press and the media through our portals because, for example, the DAM that they use is not really mobile-enabled, it’s not properly printed, and stuff, and so they put the content from the DAM in front of the media when there’s tournaments and when there’s events that they need to cover. Or we have guys like Somfy, which is a big manufacturer of home automation devices, they’re doing partner portals and providing all the content to their partners, to their resellers like product imagery, data sheets, and so on and so on. So we have a beverages vendor from the US who is using that as a product information portal, bringing together, for example, content from the DAM together with content from their Salsify PIM in this case, and really displaying that data or providing that data to their departments. For example, to see which marketing material is missing for which market. So a lot of different use cases and you see a lot of different audiences that have different requirements that not necessarily can be covered with the DAM alone.CHRIS LACINAK: 31:34
Great, and can I ask what are you particularly excited about in DAM in 2024 or at Henry Stewart DAM LA or anything that’s caught your attention or that you’re particularly focused on?REINHARD HOLZNER: 31:47
Hmm, good question. So what happens in DAM, I think, is that everything professionalizes, everything grows a lot. We see also transactions in the marketplace, going on mergers, companies taking up other companies. I hope that in the future, this will be even going into a more interesting direction that we see larger players in the marketplace that have more influence. The thing is we have a very fragmented DAM marketplace right now with, I think, over 220 vendors out there competing in the marketplace, and it will be very interesting to see if this consolidates because that would probably make things easier for the clients because they have a more complete offering for all those different units that are out there.CHRIS LACINAK: 32:37
David Sultan from OneTeg. David, thanks for agreeing to talk to me.DAVID SULTAN: 32:41
Nice to see you.CHRIS LACINAK: 32:42
Could we start off by you just telling me about OneTeg and what you guys do?DAVID SULTAN: 32:46
Sure, so OneTeg is the integration platform as a service, and what we do is we connect any system to any system, kind of like Zapier, but our focus is on digital asset management, product information, and e-commerce. So we’re able to make integration a lot easier, a lot faster, easy to maintain, easy to deal with upgrades, and just making the level of effort to your customers a lot easier to manage. So instead of having big projects, it’s a lot smaller projects, and you can predict a little bit more that.CHRIS LACINAK: 33:17
That sounds like a good goal, so it sounds like kind of creating more predictability and efficiency around the integration process, which can be unwieldy and a lot of risk as far as costs and time. That’s great.
Could you give us an example of maybe how, and you don’t have to use names, it’s okay if you want to anonymize it, but just how like a customer has used OneTeg, give us an example of that.DAVID SULTAN: 33:43
So we have a customer who uses OpenText as their DAM and using Syndigo as their syndication engine. So whenever he needs to go to Amazon or to any of those other marketplaces they sell beverages, so we had to connect their assets from their DAM to their they had a separate PIM which is it’s like in a separate PIM system, it was an in-house PIM, and we had to syndicate it to Syndigo. So we basically are marrying all of that information, a very complicated flow, and ensuring all of the information is married up between the product, the images, into the website, into the marketplaces.CHRIS LACINAK: 34:21
Okay, all right, that’s great. Thank you, that’s helpful. And what’s one of the features that’s on your product roadmap that you’re most excited about?DAVID SULTAN: 34:29
So when we first launched it a couple of years ago, it was really about just being kind of more of a generic iPaaS solution focusing on DAM and PIM, and we still are, but what we’ve realized is that a lot of our customers, what they really want is a quick way to get into a project. So we start building a lot of templates, so a template, so we call it a recipe, so a template or recipe, so say for example you want to connect inriver to MediaValet, a DAM and a PIM, we can very easily spin up a recipe that already has done the, already has all of the hooks between those two systems, and then we can, you can use a template to expand to your own flow that you need to build in your environment. So that’s like a big thing we’re doing as well, and we also, this is not short term, but long term, we also trying to look for an AI in order to help the developers or whoever is actually building the flows to use AI to generate the flow for it by putting prompts. That’s kind of a little bit longer in the roadmap.CHRIS LACINAK: 35:27
Okay, interesting. Yeah, that’s an interesting use of AI. It makes sense; it’s going to be different than how the platforms are using it. So that’s interesting to hear. Eric Wengrowski, CEO of Steg AI. Eric, can you tell us a little bit about Steg AI and what you do?ERIC WENGROWSKI: 35:41
Yeah, sure. So Steg is a state-of-the-art watermarking company. So we do watermarks for a variety of use cases, everything from leak protection to identifying generative AI, deep fakes, things like that, and we do it all with state-of-the-art watermarking technology that we’ve developed in-house and we’ve patented. We work with many of the DAMs here at Henry Stewart to bring our tech to customers.CHRIS LACINAK: 36:06
Great, and can you tell me, in your roadmap, what are you most excited about that’s on the horizon that you can talk about?ERIC WENGROWSKI: 36:17
Yeah, sure. So, you know, the benefit that Steg brings to our customers is primarily around security, and so, you know, with the explosion of deep fakes and generative AI, seeing is no longer believing. I mean, like, I’ve been working in this field and developing AI algorithms, you know, for 10 years now.CHRIS LACINAK: 36:38
Okay.ERIC WENGROWSKI: 36:39
And a lot of the times I can’t tell the difference between something that came out of a camera and something that came out of an algorithm. So, it’s getting to the point where, you know, even relying on people better than me, forensic experts, aren’t going to be able to tell the difference, and just given the sheer volume of content that people consume over social media and things like that, we really need tools to help understand what’s real, what’s trustworthy, what’s synthetic, what’s organic without labeling something as like, you know, just good or bad, just telling us more about the provenance. So, you know, we’re working right now, we’ve created tools to help identify the origin of content, what’s trustworthy. This is for everybody from generative AI companies to federal governments who are wanting to ensure that there’s a sort of a clean communication channel between them and their nationals.CHRIS LACINAK: 37:31
Great. Yeah. And maybe could you help us wrap our heads around it a bit more, maybe but give us in a case study, and you don’t have to name names if you need to anonymize it, or but just help us understand how some of your customers are putting your technology to use.ERIC WENGROWSKI: 37:46
Yeah, sure. So a couple of years ago, we were approached by a company that was experiencing million-dollar on average leaks for every one of their products that had launched for the past three years, and they were having multiple launches a year that were all leaking ahead of time. This is a consumer electronics company. So they were working with a DAM who we decided to partner with that was great, but, you know, the problem was they really couldn’t tell where these leaks were coming from. Is this stuff that was internal, people on their own team, was it any of their vendors, partners, anything like that. So we integrated Steg’s watermarking technology with their DAM, so automatically in the background whenever they were sharing assets out or any step with the creation process, we were applying new watermarks every time. So if anything leaked out, we could always go back and identify the source. And when leaks happened, and they’ve happened many times, we’ve always been able to trace back and identify the source of the leaks and help the customer plug this extremely costly problem.CHRIS LACINAK: 38:47
And last but not least, what’s the last song you added to your favorites playlist?CHRISTOPHER MORGAN-WILSON: 38:52
Orange Logic. Dance, Dance by Ryan Prewett.SHANNON DELOACH: 38:55
Censhare. An oldie but a goodie, it was Public Enemy and then the Hour of Chaos. So for some reason, I just had a hankering for that song, I added it to my playlist.MELANIE CHALUPA: 39:05
Frontify. Do What I Want by Kid Cudi somehow wasn’t in my playlist before today, and now it is.JOHN BATEMAN: 39:11
Tenovos. Iron Maiden, Run to the Hills, that’s one you probably haven’t gotten.BRIAN KAVANAUGH: 39:16
Bynder. Square One by none other than Tom Petty, and so I’m a big Tom Petty fan but that’s not one that I’d heard, and so I added it this past weekend.BRÓNA O’CONNOR: 39:25
MediaValet. Billie Eilish, What Was I Made For, and that was because I saw her perform it at the Oscars a week ago, so that was that.CHRIS LACINAK: 39:33
You were at the Oscars yourself?BRÓNA O’CONNOR: 39:35
No. I wish.CHRIS LACINAK: 39:36
Let’s just say you were. Let’s just say you were.BRÓNA O’CONNOR: 39:39
Yeah, I was there.JAKE ATHEY: 39:40
Acquia. I’m a girl dad, so I’m gonna go with Taylor Swift, and one that really gets me revved up is Ready For It, and that’s from the Reputation album.REINHARD HOLZNER: 39:47
Smint. It’s that Elton John, Dua Lipa song.CHRIS LACINAK: 39:51
Okay, all right, all right, great, wouldn’t have guessed.DAVID SULTAN: 39:55
OneTeg. So I like John Prine, I know he’s, I think he died a few years ago, but I love his music, it’s country music, and I think the song, it’s called That’s the Way That the World Goes ‘Round.ERIC WENGROWSKI: 40:09
Steg AI. All right, so I didn’t add it to my favorites playlist, but I took, so my wife and I just had a baby a few months ago, as a present while she was still pregnant, I took her to see Taylor Swift here in LA.CHRIS LACINAK: 40:27
Best husband award of the year.ERIC WENGROWSKI: 40:29
Yeah, I’ll take that for this one. So, you know, I’m, I would not describe myself as a Swiftie, I’m definitely not a hater, but you know, my wife is a real Swiftie, and so I was like, hey, you know, I’ll go, it’ll be fun. Best concert I’ve ever been to, hands down. Yeah, SoFi, it was awesome.CHRIS LACINAK: 40:47
All right, so give me a favorite Taylor Swift song.ERIC WENGROWSKI: 40:51
Oh, I like Colors.CHRIS LACINAK: 40:52
Now, there’s a fun session that happens at every Henry Stewart I’ve been to at least called Stump the DAM Consultant. It’s hosted by Jarrod Gingras from the Real Story Group. A number of brave consultants get on stage, the audience asks a bunch of questions in an app, Jarrod Gingras looks at the upvotes to see what are the highest priority questions or the ones that have been voted on the most, and asks those of the consultants. Now, all the consultants put on headphones with music so they can’t hear the other consultants answering, and at one at a time, they answer, and then the audience votes on who has the best answer. And because I don’t have the approval of all the consultants on the stage or Jarrod, I’m going to include just answers from Kara Van Malssen from AVP in this one to give you a little taste of what that looks like and sounds like; it’s a fun event. So, a little bonus for you here.
If we’re currently in DAM 4.0, what will DAM 5.0 be?KARA VAN MALSSEN: 41:53
Okay, so my answer is, I don’t think that there will be a DAM 5.0. I just, I luckily, I did my homework and I went to Jarrod’s session earlier, and it got me thinking about this exact question because as he was describing it, it just seemed more and more to be not DAM anymore, as kind of a content convergence and, you know, we have these beautiful and massive content orchestration engines. It seems like the concept of DAM as we know it today, DAM or MAM, as this kind of it just, that idea makes it a silo in and of itself, and I think that puts it into this corner which I just don’t see the future being. So, I just don’t know if there is a DAM 5.0. I think it’s an evolution. If you have a kid that has a Pokemon and you know how the Pokemon work, they go from like the basic Pokemon to evolution 1, 2. And I think by the time you get to evolution VMAX, you know, it’s not even the same character anymore, and that’s the reality.CHRIS LACINAK: 43:02
When will AI tagging actually work right?KARA VAN MALSSEN: 43:08
Okay, so my question is, who’s your DAM vendor? Because it should already be working. So if you don’t have it working, you come see me and we help you find a new one. Just kidding. Okay, in all honesty, I think where we are in that space, the maturity is pretty good for specific types of use cases. So, I think you have to get specific on what you want it to do. So if you’re trying to do things that are more visual, object recognition, computer vision, what’s in the photo, what colors are in this photo, what’s that object, things like that. There’s pretty good capabilities there now that are readily available. I think the harder part and maybe I’m not sure this is what you’re trying to get at is when we’ll be able to not have humans do any kind of metadata entry. I don’t know if we’ll ever be quite there. There’s certain metadata, contextual information, provenance information, information about what campaign was this part of, what project was this a part of, what are the rights to this image, what’s the credit line, should it credit the AI that created it. You know what, all of those kinds of things, I don’t think we’re necessarily ever gonna be there. So there’s just a certain amount that I think that the AI tagging can and can’t do. But I think there’s a level of maturity that is pretty solid right now for certain use cases. So, I’ll just say it’s limited but it’s evolving.CHRIS LACINAK: 44:39
What’s the easiest AI win for a DAM when your boss is forcing a quick AI answer?KARA VAN MALSSEN: 44:44
The quickest AI win right now… Okay, well it’s, I think it’s kind of similar to the last question, which was some of that tagging. But I actually think the very easiest one you can unlock pretty fast is speech to text for video and audio. So that’s pretty good. You know, you might have to do some editing. What’s so funny back there? Okay, vote for Kara. So, speech to text is pretty, you know, that’s an easy one. And you can just get all of that transcription of your audio and video, and then you have so much searchable text. Boom. Easy way. Go for it. Do it tomorrow.CHRIS LACINAK: 45:30
If you had to use a song to describe a DAM, what song would you pick?KARA VAN MALSSEN: 45:37
The first word of this song title is a curse word, but it’s “b” with those, you know, special characters, better have my money. It’s expensive, right?CHRIS LACINAK: 45:51
So here we are at the end of the Henry Stewart DAM LA conference. It’s been a great conference. What are some of the takeaways and themes from this year? One is that a lot of people were talking about portals. Last year, that was a word that was being used, but we mostly saw it on the DAM and technology provider side. This year, I heard a lot about it from users. People that were talking about real use cases wanting to create seamless user experiences on both the download and the upload side. Speaking to very specific audiences both internal and external to their organization, and it felt like a thing that was new in a new practical way. Speaking of practical, another thing that was that felt new this year was we heard a lot about AI. Last year felt a bit more wide-eyed than it did this year. This year, people had clearly put it to use. They had grappled with the issues more. There was skepticism but helped mix with healthy enthusiasm, and we just heard a lot about real-world AI applications, conversations that were happening in organizations, proof of concepts, and then day-to-day use. We still heard a mix of perspectives but it felt like a new mix, a healthy mix, and something that I think represents the progress of how organizations are using AI. That was interesting and fun to hear about. Lastly, I’ll just say that the vibe in general was really good. It felt like there was more energy this year than last year, and not to say last year was bad, but there was just something this year, there was a momentum. There was a lot of great engagement. I think the content and the program was really good this year compared to last year, and not to say it was bad, but just this year felt exceptionally good. It felt cohesive. It had people talking in the coffee breaks, at the lunches, you know, there was a lot of conversation around the program, which just meant to me that they nailed it on the authenticity of the topics, and that it was resonating with people, so that’s great. Whoever did the programming did a great job. I will say one thing that was missing, and there was one company that was representing this, actually, there were a few companies that were representing this, but it just wasn’t a topic that came up much, which was content authenticity. I heard about it in one session that I attended. There was one vendor, Steg AI, that had a booth. FADEL was here, and then there was one other company I think they were called Verify that was here in the audience. They were focused on rights management and one or two use cases for content authenticity, but I was surprised that there wasn’t more there. Now, it’s not a super sexy topic, you know, security is not the most fun thing to talk about, but it’s been bubbling up so much this year, and with the massive amounts of content generation that’s happening, with the questions around content authenticity, you know, calling real things fake and calling fake things real, and the meaning and potential impact that has to DAMs and archives is huge. So, I was just surprised that there wasn’t more about that, but I bet that that, you know, will be a conversation that we’ll hear a lot more about next year. That’s going to be a prediction for next year, so we’ll see. Anyway, it’s been a great time. I hope that you’ve enjoyed the content around the Henry Stewart DAM LA recap, and remember, DAM right because it’s too important to get wrong.
Thanks for listening to the DAM Right podcast. If you have people you want to hear from, topics you’d like to see us talk about, or events you want to see us cover, please send us an email at [email protected]. That’s [email protected]. Speaking of feedback, please go to your platform of choice and give us a rating. We would absolutely appreciate it. While you’re at it, go ahead and follow or subscribe to make sure you don’t miss an episode. You can also stay up to date with me and the DAM Right podcast by following me on LinkedIn at linkedin.com/in/clacinak. And finally, go and find some really amazing and free resources focused just on DAM at weareavp.com/free-resources. That’s weareavp.com/free-resources. You’ll find things there like our DAM Strategy Canvas, our DAM Health Score Card, and the Get Your DAM Budget slide deck template. Each one of those also has a free accompanying guide to help you put it to use. So go get them now.
Crafting a Winning DAM Strategy
14 March 2024
In today’s digital landscape, managing digital assets effectively is crucial for organizations of all sizes. A well-defined Digital Asset Management (DAM) strategy not only ensures that assets are organized and accessible but also aligns with broader organizational goals. This blog will explore the essence of DAM strategy, its components, and how to create a winning strategy that maximizes the value of your digital assets.
Understanding DAM Strategy
DAM strategy is often misunderstood. It is more than just a collection of goals or a response to problems. A successful DAM strategy is actionable, providing a clear roadmap for how to manage digital assets in a way that supports organizational objectives.
Many organizations fall into the trap of stating ambitions without a concrete plan. For instance, saying “we want to maximize the value of our digital assets” is not a strategy. It’s essential to differentiate between aspirations and actionable strategies.
The Importance of a Clear Strategy
A clear DAM strategy helps organizations avoid common pitfalls such as resource misallocation and misalignment with business objectives. Without a focused strategy, organizations may struggle to harness the full potential of their digital assets.
One of the key tools in developing a DAM strategy is the DAM Strategy Canvas, which helps organizations articulate and execute their strategies effectively. This tool guides users in identifying challenges, defining use cases, and outlining action steps to achieve their goals.
Components of a Successful DAM Strategy
To create a winning DAM strategy, organizations should focus on several key components:
- Identify the Challenge: Understand the specific problems that need to be addressed. This could range from issues with asset accessibility to challenges in user satisfaction.
- Define Use Cases: High-level use cases should be identified to understand who will use the digital assets and for what purpose. This is crucial to ensure that the strategy aligns with actual user needs.
- Prioritize Use Cases: Not all use cases can be addressed at once. Prioritize them based on the organization’s goals and the resources available.
- Outline Action Steps: Determine the actions needed to enable the prioritized use cases. This may include technology investments, process improvements, or governance enhancements.
- Define Success Metrics: Clearly articulate what success looks like for each use case. This will help track progress and adjust strategies as needed.
The Role of Stakeholders
Engaging stakeholders throughout the DAM strategy development process is vital. This includes senior leadership, technology partners, and end-users who will benefit from the DAM system. Their insights and feedback can provide valuable perspectives that shape the strategy and ensure buy-in.
For instance, senior leadership can provide guidance on organizational goals, while technology partners can offer insights on feasible solutions. Involving end-users helps ensure the strategy addresses their actual needs, increasing the likelihood of successful adoption.
Implementing the DAM Strategy
Once the strategy is defined, the next step is implementation. This involves translating the strategy into actionable plans, setting timelines, and assigning responsibilities. Regular communication with stakeholders is essential to keep everyone informed and engaged throughout the implementation process.
It’s also crucial to monitor progress and make adjustments as needed. This could involve conducting regular check-ins, gathering feedback from users, and analyzing performance metrics to ensure the DAM strategy remains aligned with organizational goals.
Evaluating Success and Continuous Improvement
After implementing the DAM strategy, organizations should continuously evaluate its effectiveness. This involves measuring success against the defined metrics and gathering feedback from users to identify areas for improvement.
Continuous improvement is key to maintaining an effective DAM strategy. Organizations should be agile, adapting their strategies as the digital landscape evolves and new challenges arise.
Conclusion
Crafting a winning DAM strategy is essential for organizations looking to maximize the value of their digital assets. By focusing on actionable plans, engaging stakeholders, and committing to continuous improvement, organizations can create a robust framework that supports their broader objectives and drives success.
For those interested in diving deeper into DAM strategy, consider leveraging the DAM Strategy Canvas as a practical tool to guide your planning and execution.
Transcript
Hello, welcome to “DAM Right, Winning at Digital Asset Management.” I’m your host, Chris Lacinak, CEO of digital asset management consulting firm, AVP. The topic of focus in today’s episode is DAM strategy. It’s almost easier to talk about what strategy is not than to talk about what it is. Strategy is not hopes and ambitions. For instance, it is not a strategy to say that we want to maximize the value of our digital assets. Strategy is not simply the opposite of a problem statement. For instance, it is not a strategy to diagnose the problem as no one being able to find the assets they need, and then to simply say that your strategy is to ensure that people will be able to find the digital assets they need. Strategy is not an observation or a statement, such as our organization will be the premier example of what effective digital asset management looks like. Strategy is not a priority. It’s not a strategy to say that user satisfaction is your main focus over the next 12 months. And strategy is not a goal or result. It’s not a strategy to say that we will have 10,000 users or 1 million assets in the DAM by such and such a date. It’s not that there’s anything wrong with any of these statements, of course. They all have a place in the process and messaging. It’s just that none of them are strategies. But statements just like these get used as strategic language all the time. And the outcome of having a bad strategy, or even no strategy, is that it leaves the organization unable to harness its power in a focused and cohesive way in order to achieve goals, dreams, and overcome challenges so that it can thrive and succeed. So what is a strategy, you might be asking? And more specifically, what is a digital asset management strategy? I’m so glad to have Kara Van Malsen with me here today to help answer that question. Kara is someone that thinks deeply about digital asset management and the organization that surrounds the practice. Kara is a thought leader, an expert practitioner, and an amazing communicator. She’s the creator of the DAM Operational Model, which we use in our work at AVP routinely, and which is available for free to anyone who wants to put it to use for themselves. And most recently, Kara has created the DAM Strategy Canvas, along with a guide on how to put it to use. This most recent piece is why I’ve invited Kara to join us today, so that we can better understand why a DAM strategy is important, what a DAM strategy is, and to help you create your own. Kara has been working in digital asset management since 2006, and is one of the leading thinkers and practitioners in this space. Of course, I’m biased, because Kara is also a partner and managing director at AVP, but that doesn’t make it any less true. You’ll hear it for yourself in this episode. Kara is driven by a passion for helping organizations build impactful DAM programs with deep expertise in systems thinking, user experience design, library science, and business analysis with extensive DAM experience. Her portfolio ranges from Fortune 500 powerhouses to esteemed cultural heritage institutions and transformative nonprofits. Beyond her consulting role, Kara frequently shares her insights at conferences and workshops around the globe. She has taught at NYU and Pratt, and has been involved as a trainer in a number of amazing global initiatives, including ICROM. Also, she’s just simply an awesome person, and I’m thrilled to have her launch the inaugural episode of DAM Right with me. Let’s jump in, and remember, DAM right, because it’s too important to get wrong. (upbeat music) Kara Van Malsen, welcome to the DAM Right podcast. I’m so excited to have you here today to talk about a topic that is near and dear to your heart, digital asset management strategy. You’ve just written a piece on this that we’re gonna dive into in depth, but one of the reasons that I’m so excited to talk to you about this today is because I think in the conference circuit, surprisingly, strategy is a topic that doesn’t get talked about much. So I think it’s really important, and I’m glad that we have someone like yourself who is a thought leader in this realm and is an expert practitioner to talk to us today. So thanks for joining me, I appreciate it.
Chris Lacinak: 04:03
Yeah, thanks, Chris. I’m excited to be here, and looking forward to talking about DAM strategy.
Kara Van Malssen: 04:07
Before we dive in, I’d love for you to just tell me a bit about yourself. What’s your background? What’s your history? How did you get into digital asset management? And to give us some insight into what your approach is today.
Chris Lacinak: 04:19
So my background is in archives and specifically moving image archives. So I have a master’s degree in Moving Image Archiving and Preservation from NYU. And so my intention was to go into film and television preservation archiving. This was in the early 2000s, so this was really pre-YouTube, pre-internet video, but kind of started in the digital space early on. And so I was working in that kind of around 2005, 2006. And, you know, it’s fast forward some years that we were kind of working on, how do we get all these things into digital form? What’s gonna happen when everything’s shot digitally and file-based media? Few years later that happened. So everything was digital. And it was, you know, kind of, it was no longer the case that there was such an enormous difference between the needs of video content versus other kinds of content. It was just going into big pools and buckets of content in general. And so that all needed to be cared for in a way so that it could be leveraged by organizations to help them kind of fulfill their mission or whatever they needed to do with it. And so it just evolved from there. It was just like, well, it’s all digital now, let’s figure out what to do with this stuff. So that’s kind of how I got into it and I’m still into it today.
Kara Van Malssen: 05:42
Do you think that that background gives you a different perspective than maybe folks that have come at it from a different angle? Do you think that that gives you any particular, you know, unique insights?
Chris Lacinak: 05:54
I think there are several places that people come from that are in this field. So it could be that they have an archive or library science background like me. Some people come to it from the production side, the creative operations side, and they sort of realize, you know, this could all be done so much better if we just had a better handle on these assets. I do think those two perspectives are very different. Those of us who have library science type backgrounds are kind of standards driven. We’re very much about, you know, just making sure that the librarian side of things is all right. Whereas the other people coming from a creative background are gonna see it from the perspective of the creative team and the kind of the operations and sort of the end product of the marketing collateral that you can produce from these assets or kind of other product related collateral. So I think we come at it from different perspectives. And as you evolve into the career, you start to broaden your understanding of, you know, the perspective. So at a certain point, I don’t know, it all blends together. I think I have other interests that I bring to this space. But things like user experience design is something I’m very interested in and passionate about kind of just in strategic thinking in general, which is I think how I ended up landing on let’s do something about DAM strategy. So.
Kara Van Malssen: 07:20
Yeah, it’s interesting. Anybody that knows you knows that you are always creating and thinking and trying to improve on things that are done. And interestingly, things like operational models and user experience design and strategy are almost certainly not in film studies or archival programs or digital asset management programs. So you’ve shown that you’re bringing your interests to the table outside of your background and kind of formal studies, which is great. So let’s talk about the digital asset management strategy canvas. You’ve created this piece. It’s a kind of one page piece and it’s got an accompanying guide that explains like how to use it. So, you know, I’d like to focus on it as a way to talk about strategy at large, like what strategy looks like and how people should approach it. So could you tell us to start, could you just give us an overview of what the canvas is all about and kind of how it came to be?
Chris Lacinak: 08:24
Yeah, so the canvas is kind of, it’s a nod to those great canvas creators out there, like the folks that created the business model, the Business Model Canvas, the folks at Strategizer and things like that. So I sort of love those types of simple visual kind of thinking and idea generation tools. So I’m really drawn to that sort of thing. So that’s, first of all, where some of the inspiration came from. But in general, the idea behind the canvas is just to have a tool that’s going to guide you in thinking about your DAM strategy and kind of give you a place to jot down and kind of generate ideas about what should be in your strategy. So it’s not like the strategy is the canvas, it’s more of a thinking tool to help you plan, ideate and kind of have conversation around the creation of a strategy for digital asset management. So it’s just a way of organizing your thoughts and ideas and kind of being able to work with those in a way that’s sort of flexible and fluid in a visual sort of form. You can use it in person, if you were to kind of be in a meeting, you might have it in a larger form printout or people could have their own copies, but it’s also nice, something you can throw in a virtual whiteboard in a Zoom session and throw sticky notes on it and things like that. So that’s kind of what it is at its heart. It’s a planning tool and a thinking tool.
Kara Van Malssen: 09:55
Thinking about using it as a tool, should someone who’s putting it to use think about the steps that you lay out on the canvas as a way to arrive at a strategy itself is these individual components are not the strategy, they’re helping you arrive at your strategy. Is that the right way to think about it?
Chris Lacinak: 10:15
Yeah, I think that’s fair to say. I think what you’ll ultimately come up with and document in that canvas will amount to a strategy, but a strategy and the success of a strategy comes down to how it’s articulated, how it’s communicated, how it’s shared, how you’re kind of managing conversation around it. So I don’t think you can just say, we made a canvas, we’re done, we have a strategy, let’s go. So ultimately you’ll have to synthesize what you have there, get it in a form that’s meaningful to your stakeholders in order to generate buy-in and support and trust and things like that. So just to help everybody align, but it’s a great conversation starter. So if you’re working with stakeholders as you’re generating a strategy, it’s a way to kind of help guide that conversation. It’s really what it’s for. But the totality of the things you’ll capture in the canvas should make up the DAM strategy. These are the things you really need to think about and be concerned with making decisions on as you’re creating a DAM strategy.
Kara Van Malssen: 11:16
For people who don’t have the DAM strategy canvas in front of them, haven’t seen it yet, could you walk us through kind of what, and this might be too big of an ask, but kind of what some of the salient steps are, how someone would work their way through it, like what are the components of the canvas?
Chris Lacinak: 11:33
Yeah, I’ll try to do that kind of succinctly since yeah, I could go on and on, but it starts with the question of what is the challenge that we’re addressing here? So if you think about strategy in general and kind of go back to like this strategy, kind of big thinkers, strategy comes out of military originally, and then in the late 20th century, mid to late 20th century is kind of adapted to corporate strategy and business strategy. And both of those cases, the question is how do we win? So if we’re in a military context, we’re thinking like how do we win this battle, this war? In a corporate strategy, it’s like how do we win this category or how do we differentiate in this market? And so people now apply strategy kind of at different layers of an organization, but the ultimate thing is it comes down to identification of a problem that you need to overcome or a challenge or an opportunity that you’re presented with, how you’re gonna go about overcoming that, and then what are the action steps you’re gonna take? And so that is how, that is kind of the root of the Digital Asset Management Strategy C anvas is kind of thinking about it that way. So if the first thing you need to think about is what is the challenge or problem we wanna overcome? That’s the first question you would work through on the canvas and try to get alignment around what really is that problem. The next set of things that we recommend that you work on, and this is all laid out in the guide that accompanies the canvas, but I would say the next step in my suggestion would be to think about the use cases. So that’s kind of the heart of this DAM Strategy Canvas. If you think about a strategy being a response to it, a particular challenge, diagnosis of a challenge, a guiding policy, and then a set of actions, what we’re arguing with this DAM Strategy Canvas and this approach is that the guiding policy piece is the use cases you’re going to be addressing. So that’s a really critical part of it, which use cases, and this is, in this case, we’re talking about high level use cases. And that’s important. It’s like not who needs to do what with digital asset management technology. That’s not the question you should be asking. It’s more about the assets and what they need to do with them. And then the accompanying piece of that is which assets and which metadata allow them to answer the questions they need to use those assets effectively. So that’s kind of the second step is thinking about those use cases. And then we get into the prioritization of those use cases. And then finally, the next question is, is to enable those use cases, what are the actions we’re going to need to take? And so the canvas has a bunch of prompts to get you thinking about the different things you’re going to have to be thinking about in order to deliver on those use cases. So that’s like, do we need technology? Do we need in process improvement? Do we need data quality improvement? Do we need governance? See things like that. So it’s kind of guiding your thinking around which actions are going to be important to deliver on those use cases. And then the final step is what does success look like? And I think that you could do that early, but I like to think about that kind of coming at the end once you’ve gone full circle from this challenge you’re addressing to, okay, what does success look like? What does it look like if we win, if we achieve our goal? So that’s the overview of the strategy canvas in the nutshell.
Kara Van Malssen: 15:07
That’s fantastic, thank you. That’s a great description. And it strikes me as you’re talking, I wonder if you would agree with this statement or not. It seems to me that that success, what does success look like, might for many people be the only thing that their strategy is, right? We want to be able to have assets in the hands of the right people at the right time, whenever they need it with the right information, right? That’s kind of what success looks like maybe, or we want to leverage our digital assets to increase revenue, something like that. But I love that you, before you get there, you’re actually kind of laying out this process that says, how are we gonna get there, those actions and broken into categories. Does that sound right? Am I thinking about that right?
Chris Lacinak: 15:57
Absolutely, and actually, my thinking on strategy in general derives a lot from Richard Rumelt and his book, “Good Strategy, Bad Strategy: The Difference and Why It Matters.” And he criticizes a lot of what he calls a social contagion of the way strategy has been deployed in our society today, which really is just a set of ambitions. Like exactly like you said, it’s just those success things. It’s just, we want to do X. And so he, that idea of the strategy is a diagnosis of the problem, a guiding policy and a set of actions to get you to that goal. It’s a lot more concrete and tangible. It’s not just, we want to reach this goal. We have this set of ambitions. And also what can tend to happen is people get very lofty about those ambitions and the action steps to get there are lost. And they’re not part of, if they’re not part of that conversation, it becomes really hard to see what it’s gonna take to achieve those. And so forcing yourself to think through this in a more kind of diligent step-by-step way to some extent will kind of help, I think drive the success of actually reaching some of those ambitions, rather than just being kind of out there as lofty goals that we keep trying for and not somehow not hitting. I think that’s the risk.
Kara Van Malssen: 17:21
I love that it’s rooted in action. That’s fantastic. So I wonder if you could tell us why now, why did you create the DAM Strategy Canvas now? What was the need that you saw or the impetus for making it happen?
Chris Lacinak: 17:35
It comes from our experience with our clients. So on the one hand, we have certain clients who will come to us and say, “Can you help us with the digital asset management strategy?” And so that’s kind of forced my thinking around this topic. But then we also have some organizations we work with that come to us that just say, “Can you help us implement this tool?” And there’s not a lot of strategic thinking around it, a lot of prioritization that’s going into it. And so in those cases, we almost have to force the conversation around strategy. So if we, and again, we kind of come back to the core of what strategy is and what it does, it helps you scope, it helps you figure out how to use limited resources, and it kind of helps you figure out how to set priorities so that you can achieve goals. So we have to do some of that thinking with our clients, even if they’re not thinking about it. And so that just is a recurring theme in the work that we’ve been doing over the years. And so I wanted to kind of create a succinct and repeatable method that we could use in our work with our clients to help kind of guide these conversations, as well as provide that as a tool for anyone else who’d like to use it. So that’s the sort of why now is like building over time as we just continue to run into the same issues over and over again. Again, lofty set of ambitions, very short timeframes to reach them, which were quite unrealistic in many cases with some of those implementation projects that we were doing. And so we would need to start and say, well, what use cases are we solving for? And what is this end state we’re trying to reach now? And see if we can set some priorities within those parameters to help make it more tangible and achievable.
Kara Van Malssen: 19:30
Yeah, that makes sense. So again, it’s rooted in kind of your own work, very pragmatic and practical. So you’ve been putting these concepts to use for a while before creating the canvas.
Chris Lacinak: 19:42
Yeah, absolutely. I think we’ve been using some version of this for a while. So this was the codified edition of the work that we’ve been doing.
Kara Van Malssen: 19:51
When I look out at the landscape of organizations that are procuring and implementing digital asset management systems, for many of them, the implementation of that digital asset management system, they may think of as the end point, that that is the achievement of a strategy or their goal, as opposed to wrapping a strategy around the actual utilization and operation of that digital asset management program. In your work with organizations, how many do you think come to the table with a digital asset management strategy versus not having a strategy at all?
Chris Lacinak: 20:30
I mean, if we take the idea of strategy as, there’s formal strategy, like big S strategy and little S strategy. So if I’m looking at it from either perspective, I’d say a very small percentage have really thought about it in either a big way or a small way. And so what will tend to happen is, there is some problem. That’s why they decided to invest in digital asset management. And maybe it’s a problem with an existing DAM solution that needs to scale, or that needs to be expanded to, beyond one team to a larger group or to the enterprise, or we need to consolidate multiple siloed asset management system. Whenever there’s a major initiative around digital asset management, I think that’s when strategy for that work tends to become important. So it’s not like the day-to-day work needs its own strategy, it’s kind of the major initiative. So at that point, you’re investing resources, time, money, everything. You’re going to make an investment in some kind of initiative. It’s a response to a problem, but it’s not DAM for DAM sake. There’s some other kind of end state or goal you’re trying to reach. So it depends on where you are, I think in a hierarchy of DAM outcomes. So the very first level is, let’s just create a single source of truth. We need all this stuff to be in one place. It’s all over the place, it’s scattered around different file sharing systems and siloed systems and people’s personal Dropbox, and it’s on people’s desktops or videos all over hard drives. And so that’s usually the first kind of goal is let’s just get a single source of truth. So just even acknowledging like, that’s what we’re trying to do here is kind of an initial step in that strategic thinking. So it’s not just implement the DAM by X date, ’cause that doesn’t connect to the outcome. So I think making that connection is really important. And then I also want to draw the distinction between a strategy and a roadmap or a kind of a detailed implementation plan. So if your strategy is kind of guiding the decisions that are gonna drive the implementation plan, the implementation plan is like you said, it’s just get the thing launched. That is part of the plan. That’s a milestone that you need to hit in order to kind of work toward that bigger goal of single source of truth or whatever it is. But yeah, I think you need to kind of approach this as in a way that again, sequences, how you’re gonna focus on that and try not to do too much at once. I think organizations that are especially new to DAM don’t realize how much investment is gonna be, how much it’s gonna take to get to success. And I think they kind of end up getting stuck sometimes if they just go, let’s get to launch by this date, then we’ll have succeeded.
Kara Van Malssen: 23:34
Let me recap a little bit. And I’m wondering if you can expand on it a bit more, but for someone who’s listening who thinks, why do I need a DAM strategy? Some of the things I’ve heard you say so far are, it sounds like it solves a problem. That’s kind of the, it sounds like that’s where you start, right? What’s the problem we’re solving for? So it’s gonna solve some pain points. It’s gonna help you overcome some challenges. It also sounds like a part of the why would be to enable action as you’ve outlined it. It gives you some concrete steps that you can take and by you, an individual, a team, folks within an operation, DAM operation, folks outside of. What are, are there other whys that you can answer about like why should an organization implement a DAM strategy that I haven’t touched on or does that summarize it?
Chris Lacinak: 24:30
Those are, I think those are the main, those are the key points. So I think we could flip that question on its head and say what could happen if you don’t have some form of a strategy. If you’re undertaking a major initiative with regard to digital asset management, there can be a lot of, a lot can go wrong if you are not aligned with, the stakeholders aren’t aligned on what it’s supposed to solve for. And this is also change management theory 101. It’s like what problem is the change trying to solve? So that’s kind of the same core question. And then, so if you’re not kind of aligned on that, it’s easy to take on way too much. It’s easy to kind of lose time, lose money, go way off track and start to lose the buy-in and support of the stakeholders. So it’s kind of why should you do it? Well, why shouldn’t you is because there’s a lot of risk involved in this type of investment and you wanna get it right. So you’ve got to kind of get that buy-in. And the other, the end result of this is often some form of organizational change. You’re gonna ask people to change their behavior at the end of the day. Once you have this thing kind of implemented, launched or evolved to whatever state it’s gonna be. And those people need to be brought along in that process. And so that strategy is also really important for thinking about how are we gonna communicate what this is for, what’s the benefit to the organization, what’s the benefit to the individual and what should they expect when? Because that’s another thing is if you don’t have a strategy that’s guiding the prioritization and the sequencing of the work, ’cause that’s really what it comes down to, people are gonna have lofty expectations about what it means to them, when they’re gonna get some benefit from it. And if you can’t deliver on those assumptions, they’re gonna start to lose their support for it. And so this is when the tides start to turn and people kind of, they’re not gonna support the thing once it does come around, ’cause I’ve been expecting this or that and you’re not delivering that. It can generate a lot of frustration. So it helps you be clear with the organization and the stakeholders too.
Kara Van Malssen: 26:58
So it sounds like it gets people to work cohesively in alignment to overcome problems, to get return on investment, that return being probably different for each organization depending on what the value is. Thinking here about, obviously in most, if not all organizations, digital asset management is one department, one operation, one thing out of many within a larger organization, right? You might have marketing, you’ve got sales, you’ve got production or operations, other operations, you’ve got executive, an overarching company strategy. How have you seen or how do you think about a DAM strategy kind of working with, integrating with other strategies throughout a company?
Chris Lacinak: 27:48
Yeah, it’s a really good question. I think a DAM strategy has to align with the broader strategy that it sits within. So that could be that the DAM strategy aligns with just the departmental or business unit or org strategy that you’re in. So if it’s marketing, kind of the DAM strategy is aligning with the marketing strategy. But if it’s, let’s say it’s an enterprise DAM, then you are looking at the full business strategy. And what is this organization kind of trying to achieve? What’s its goals and what is it that this particular initiative around digital asset management is going to do to enable or support those goals? So there’s a strong connection between those things. So there’s some, like I said before, there’s some ambition or dream outcome for this DAM, that is what’s gonna have that connection to this broader strategy. So if it’s, so let’s take like an apparel company that is shifting to digital product creation. So they’re gonna use 3D modeling in order to kind of create, have faster time to market, reduce their carbon footprint by moving away from physical samples that are typically the way that products in that space are done, shipping them all over the world between providers in Asia, US or wherever, to kind of this 3D model. And there’s a, so that is maybe a kind of more corporate level strategy. We’re gonna shift to digital product creation in order to improve our time to market, reduce our carbon footprint, and create tailored experiences for our customers. So if you think about that bigger picture strategy, and then you step back and say, well, where does DAM fit into that? It has a huge role to play because it’s, all the files that are gonna go into that process of creating the apparel now are gonna be digital. They’re gonna need to be organized. They’re gonna need to be put into a data pipeline that allows for that information to kind of flow through the production process down to marketing and sales and kind of ultimately e-commerce and end user experience. So it’s incredibly closely connected. And I think you can take a similar type of example. Let’s take a museum. So a museum wants to, you know, their broader strategic goal is we wanna reach new audiences, engage with them in new ways, both in-person and online. So that’s like a, you know, a kind of the big picture ambition. So how does digital asset management fit into that? Again, it has a huge role to play because the museum’s digital assets are its collections, you know, images of those collections, and it’s how are we going to reach our audiences, connect with our audiences. We’re gonna need those assets in order to achieve that bigger picture goal and the data that accompanies them. And again, it’s getting these digital assets, they’re just a form of data into a data pipeline that kind of allows this bigger picture strategic vision that the broader organization has. So, and you can kind of take that down levels as well if you’re, you know, you’re the marketing department, it’s the marketing DAM, and the marketing’s overall strategy is to, you know, increase the, you know, targeting of campaigns. We need to measure the impact of our campaign and kind of hype, we need high performing, and we need more kind of feedback loops and insights and measurement as we go. So the DAM is again, a piece of data in that pipeline. It’s gonna help you with kind of getting that content out in an efficient manner. It’s gonna help with capturing data and insights about performance kind of on the other side and allow for more insightful and kind of smarter production moving forward. So there’s just a lot of ways it all connects, I think.
Kara Van Malssen: 31:42
Thanks for painting such a great picture in different contexts there. It’s interesting as you’re talking, you know, you’re talking about kind of problems of, I mean, goals and problems of an enterprise, of different departments. And thinking about the person who sits down with the canvas and we’ve said, you know, start with the problem. What’s the problem you’re trying to solve? And from what you’ve just said, it makes me wonder, you know, the person who sits down, and you kind of pointed to this earlier ’cause you said, you know, it’s about not what can you do with the DAM, it’s what can you do with the digital assets? The DAM is like a means to an end. And the problem, I guess it makes, this is a question, I’m just thinking out loud here. The problem that the person who sits down with the strategy canvas might aim at is not the problem of the DAM operation, but rather the problem of the company vision or strategy that they can help overcome. Is that the right way to think about that? Or have I got that wrong?
Chris Lacinak: 32:48
No, I think you’re right. The problem in this case, it does relate to the digital assets. So digital asset management is a solution. It’s not the problem. I mean, maybe you’d say, oh, this DAM sucks and it’s a problem. Okay, maybe that’s true. And we can kind of go down that path. But the problem you’re trying to focus in on and identify is the one of the digital assets themselves and their use in kind of delivering on some bigger goal or success criteria. So that’s generally the starting point. And so, again, that’s why I said earlier as well, like when you’re thinking about use cases, it’s not use cases for a DAM system, it’s use cases for digital assets. Who needs them and what do they need to do with them? That’s where the thinking should kind of live because you can get stuck in thinking about, again, it’s sort of like looking inward at DAM as the problem or as the solution or as the thing. And it’s all kind of inwardly focused. But if you’re not connecting the digital asset management solution to the business needs, I don’t think you’re doing it right. And so that’s why this canvas is trying to guide the thinking around that. What problem are we really talking about here? Which use cases are we really talking about here? So that you can, again, prioritize and make sure that you’re kind of solving the right thing.
Kara Van Malssen: 34:20
Again, just thinking pragmatically about the person who goes and downloads those DAM strategy canvas to create their own strategy. What do you think they need? Let’s say it’s the DAM Manager or the Director of Creative Operations or something that goes and does this. They sit down. Who else do they need at the table for this? What other information do they want to be sure to have in order to be able to create something that’s going to be useful and meaningful? What should folks be thinking about kind of as the prerequisites or preparedness that they need to come to the table with? You might be listening to this episode and thinking this sounds awesome, but how can I do this for myself? Lucky for you, you can download AVP’s DAM Strategy Canvas for free at weareavp.com/free-resources. That’s weareavp.com/free-resources. The DAM Strategy Canvas is your roadmap to creating the perfect DAM strategy all on one page. If you’re enjoying the DAM Right podcast, please rate, like, follow, subscribe on your podcast platform of choice. And stay up to date with me and the DAM Right podcast on LinkedIn at linkedin.com/in/clacinak. That’s linkedin.com/in/clacinak. Again, just thinking pragmatically about the person who goes and downloads this DAM Strategy Canvas to create their own strategy. What do you think they need? Let’s say it’s the DAM Manager or the Director of Creative Operations or something that goes and does this. They sit down. Who else do they need at the table for this? What other information do they wanna be sure to have in order to be able to create something that’s gonna be useful and meaningful? What should folks be thinking about kind of as the prerequisites or preparedness that they need to come to the table with?
Chris Lacinak: 36:20
Yeah, so I think if you’re a lone DAM strategist, more power to you, but you’re gonna wanna talk to other stakeholders. At minimum, if not fully engage them in the process. But sometimes you don’t wanna go overboard with the formalities of this. Like we’re doing a DAM strategy and you’re all invited and come to my workshop. That could be great, but it may just be, you’re gonna need to talk to people, interview them, learn about them, ask the right questions to understand how they’re thinking about it. If you’re tasked with, and let’s assume that the person we’re talking about here is tasked with some kind of digital asset management initiative. They’re leading it, they’re supposed to kind of see it through. There’s some other people that are aware of that or that kind of made a decision to invest in that. So those people you need to talk to or bring them to the table. Those are kind of critical thinkers in this space. So that’s probably the sponsors of this, whoever kind of made that decision or gave the green light to do something about it. Maybe you don’t have a green light yet, but they’re the ones that are concerned with it. So somebody in the kind of more senior leadership picture at whatever level that makes sense, that’s critical ’cause you need to get their alignment and buy-in. And then also, because we’re talking about data, we’re talking about assets at large volumes, usually that have to be stored and use technology to manage them. You’re probably gonna need your technology partners in the room too. So somebody in IT, whoever your business liaison is there to your group is gonna be important. They also don’t like it when you make major investments in technology without their input. So they’re the ones that are gonna have to deal with the technical debt down the road. So please involve your technology partners. And then I think the other group to make sure you include is the stakeholders who are the beneficiaries or those impacted by the DAM initiative. So those are probably the users or the people who are gonna be creating or contributing the assets or the ones that are gonna be downstream using it. So representatives of those who this is for, they need to have a voice in kind of setting priorities, making sure we’re clearly aligned on the challenge we’re trying to solve for and what a success looks like. So I’d say those are the three main groups, senior leadership, technology, and your major kind of stakeholder partners that are gonna be affected by it.
Kara Van Malssen: 39:01
The picture you painted for us earlier makes clear that digital asset management exists in all types of forms and fashions within organizations. It can be multiple DAMs and multiple departments. It could be an enterprise DAM. It could be no DAM Manager or kind of centralized operations around the DAM. It’s a distributed team that shares ownership or it could be a DAM operations that serves as like a centralized service to the rest of the organization. Are there models that you have seen which tend to lend themselves to being more successful at creating and executing on strategy rather than less?
Chris Lacinak: 39:42
Yes, this is a fun topic that I enjoy very much. What does the DAM literal operational optimal model look like? I think that the best model has some element of a clear sponsor or sponsors or like tightly aligned if it’s more than one person, some knowledgeable experienced kind of product owner of this system. And ideally in some, maybe it’s the same person but somebody who’s creating the rules, the guidelines, the standards and all that stuff. So at some level, a central set of thinking and kind of guideline and guardrail creation for the system. That works best when it’s like a small team, at least like a minimum. And then again, it depends on the scale. But so I think hub and spoke models can work really well. So you’ve got that central DAM team who are kind of like making the major decisions around the system and its evolution and how people should use it and what’s available to them and taking input from users around feature requests. And they’re the ones that interface with the vendor, et cetera, et cetera. And then maybe there’s for, if this is a large enterprise kind of model, let’s say, there’s individual teams or business units who are sort of tenants of that system or users of it. And they probably have a point of contact that’s kind of the lead on their side. And that person is the liaison with the central team. I really liked that model for a very large organization. So at a very small level, if you’re just kind of in a working group and like the DAM is just for like a very small, creative team, I think you can get away with a shared kind of contributor model where, everyone who’s gonna be adding assets sort of collectively manages it, but that falls apart really fast. If nobody’s sort of mining the store and kind of, so if you took your like grocery store and you just let all the vendors and suppliers just put whatever they want on the shelves, however they want, and maybe they forgot to put the price tag on some stuff and like hook it up to the register, it would be chaos pretty quickly. So I don’t love it. I know it’s the reality in a lot of cases where you just need to have, nobody has the time to sort of be the oversight person and it’s just a small DAM and you’re not a very big team. I think you can get away with that for a little while. But as it grows, as it scales, and these things tend to do as we’re kind of more in the space where audio, video, image, is the predominant form of content over text, and that’s kind of what our organizations are producing as well, then we’re only gonna need to kind of increase the kind of operation around these assets. And so some kind of smart expert thinking to guide people in how to use the system I think is always gonna be critical.
Kara Van Malssen: 43:06
For folks that are in that less than ideal scenario that you painted, it sounds like mitigation of the risk that comes along with that could be in the form of thorough documentation. I mean, it points right at the heart, really your whole response points right at governance, it sounds like. Does that sound right?
Chris Lacinak: 43:25
Yeah, that’s true.
Kara Van Malssen: 43:26
For folks that are in that situation and they can’t change tomorrow, like what would be the words of wisdom that you would give to them about how to help ensure that it doesn’t lead to disastrous outcomes?
Chris Lacinak: 43:39
If they’re in that situation of sort of a shared contributor model and they’re thinking about it, that means congratulations, like you’re the one that’s gonna get stuck with the DAM problem, but that’s okay ’cause you care. So you’ve identified this isn’t gonna work. I’m talking to you like this person that you just talked about, ’cause you had that insight and you realize it’s not working and you’re kind of gonna push for some change now. Doesn’t mean you’re gonna get stuck with it forever, but you’re the one who as a user, as a beneficiary of the tool are saying, raising the flag of, hey, this isn’t working, this is not right, we need to do something different. We really need somebody who’s in charge of this thing because it’s a big mess, no one can find anything. It’s not working, it’s not fulfilling the goals we set out for this. People are still misusing assets or whatever it is. So as that kind of whistleblower, you’re gonna be the person that’s gonna have to advocate for something different, but I think you also know best what the problems are and what’s happening as a result of that not working. And it’s probably just, what’s happening is you’re ending up in the same place you were before you had the tool. People are still squirreling away their assets on their personal DropBox and then on hard drives and whatever, they’re not contributing to the DAM and they are misusing them and they’re not complying with brand guidelines and they’re not using licensed assets appropriately and they are reshooting things that you already have footage of. So yeah, I think, raise that alarm, beat the drum and try to paint the bigger picture of what’s at stake, what’s the impact. Again, if you put on that strategist hat, think about what is it we’re trying to achieve as an organization, what does success look like and how we’re not gonna get there if we leave this as a status quo. We need to do something different. So hopefully you can kind of inspire your kind of leadership, connect with what’s their concern, what are they thinking about, what’s keeping them up at night, what are their, again, that bigger picture strategy they’re trying to work toward. That’s the best way. I think if you try to, if you just kind of whine and complain, I say this to my son all the time, stop whining and complaining. It’s not effective in getting me to give you what you want, but I guess sometimes it is ’cause he does it a lot. Anyway, don’t just do, kind of complain about what’s not working, try to figure out what does, provide the kind of constructive ideas and input and what could success look like. So yeah, if you’re that person, it sounds like you’re, you got stuck with that job and you’ve got to be the one to be the loud voice for change.
Kara Van Malssen: 46:37
So whining and complaining is one tool in the toolbox, but not the most effective.
Chris Lacinak: 46:42
I don’t think so.
Kara Van Malssen: 46:43
The other thing that the focus in on governance makes me think about is you have another creation, the DAM Operational Model. And I wonder, there will be people who look at the canvas and the model, could you tell us how to think about those things as, how would you plug those together? How do they work together?
Chris Lacinak: 47:03
So the DAM Operational Model is kind of what we came up with that it’s all the things that you need to have a successful DAM operation. So it covers technology, of course, but also you have people, which people, stakeholders do you need, which are important, which processes or governance, of course, around things like decision-making, standard setting, policy creation, processes, I think I said, measurement, and of course, like goal setting and tracking in general. So, and then there’s the centerpiece, which is like the why of all this, that’s where the strategy lives. So the DAM strategy kind of sits in the, in our model it’s a circle with these seven competencies and like there’s one right in the middle. And that’s the strategy, ’cause it’s, the operational model can be used at any kind of stage of development or maturity. So you can use it one way, if you’re just starting out, you can use it another way, if you’re kind of on a business as usual path, you can use it another way if you’re on a scaling path. So, but the center part of that is always going to orient where your focus is, where your prioritization is, and sort of in that goal setting category, which guides everything, it all leads it from the strategy. So once we’ve decided our strategy, we can then create a roadmap, we can track toward it, we can measure against it, we can report on it, and we can enable and optimize all the other things around, you know, the people, the processes, the governance, the technology to deliver on that strategy. So they fit together, I guess I would say that. Strategy is the center of the entire thing that guides all of the rest.
Kara Van Malssen: 48:56
So I imagine that some people might take the DAM Operational Model, and there’s like a self-assessment or a DAM health score sheet that we have, and they might score their health on it and say, “Okay, I’m not doing so great on governance “and technology and processes.” I could imagine that someone might take that then and say, “Well, where do I need to improve in those areas? “How do I need to improve?” And think that that is my strategy. That’s, you know, if I can answer those questions, how do I do better at governance? How do I do better at technology and the areas that I’m not strong in in the DAM Operational Model? That that would be my action items towards achieving my outcomes. Is that, what would you say to that? Does, what would you say to that being, you know, how does that play off those action items in the DAM Operational Model to improve your health play off of the action items in the strategy?
Chris Lacinak: 49:51
Yeah, I mean, it’s not wrong, and there’s action items and then there’s action items. I think when I think of the strategy, it’s not action items like this task, this task, this task. I think that’s the, again, the implementation roadmap. And if you’re identifying problems with, you know, the process or the governance, and you want to fine tune them, that goes in the roadmap. And, but the initiative or in the investment in those areas is what’s going to show up in the strategy. So in the canvas, we call them key initiatives and actions. So it’s not necessarily an action item list, but it’s a set of key actions that like, or initiatives that are going to be, they’re going to enable the strategy to work. So again, it’s at a different level of granularity. So if you want to, if you’re fine tuning, what’s already there, I think that’s, again, it’s important. You want to optimize, you want to continue to, you know, continuously do that. And that’s why in the operational model, we kind of call one of those areas continuous improvement. And that’s sort of our ongoing optimization. That should be in your roadmap, but you probably have a bigger picture thing in your strategy that’s all of those fine tuning actions are working towards. So it’s just kind of, again, like it’s a different level of granularity and thinking. So the strategy itself doesn’t have, you know, individual dates necessarily for each action. It’s more like we want to achieve X and we’re going to invest in Y to do that. And so that’s really what that looks like.
Kara Van Malssen: 51:33
The analogy that comes to mind for me as you’re talking about the DAM Operational Model versus the canvas is if we think about like a car, your car running and how well it runs, who’s like, it might be the DAM Operational Model, you know, is the engine running well? Has the oil been changed? Is your windshield wiper is good? And the strategy is more about, do you know where you’re going? Can you get to your destination? Does the, you know, are you steering the vehicle in the right direction? Is that a way to think about it that works?
Chris Lacinak: 52:05
Yeah, I think so. I mean, yeah, I think I had not thought of that analogy, but yeah, totally makes sense. Yeah, the car and it’s kind of inner workings is one thing. It’s trying to get you somewhere, but yeah, the strategy is more like, where are you trying to go? And what are the steps you’re going to need to take to get there? Like, we’re going to have to get on the interstate and we’re going to have to, you know, take a left here and this and that kind of thing. So I think that works. Yeah, I like that analogy actually.
Kara Van Malssen: 52:32
I wanted to touch on one thing that’s in the, what I’ll call the guide that accompanies the strategy canvas. You use a statistic in there that comes from brand folder and demand metric that says, “77% of study participants were satisfied with their digital asset management solution when deployment was completed quickly.” And there’s other stats in there that say about how many people were basically dissatisfied when it took longer than six months. I’m wondering, why do you think that is? What’s going on there? Why do you think deployment time is such a strong determining factor of success and user satisfaction?
Chris Lacinak: 53:13
Well, I think it kind of goes back to something we were saying earlier around managing expectations and kind of getting that goodwill and support and buy-in. And when it takes too long, there’s probably multiple things at play. One is, well, you probably didn’t have really a well thought out strategy, the scope wasn’t clear, the action items weren’t clear, and most likely you took on too much. So the time to value is way too long. And I think that’s the key with something like this is when the success hinges on adoption, time to value is absolutely critical because you need those people to adopt it, to buy into it, and have to kind of be in sync with what it’s for, what’s expected of them, and by when. And if you keep kind of pushing that can down the road and kind of muddling that communication and expectation, I think people just start to get fed up and lose trust in the whole initiative. I think that’s my guess as to what’s going on. So you’re kind of poorly communicating, the execution’s kind of getting all over the place, you’re trying to do too much, you’re not having any, the short-term wins aren’t there, like the transformation that was proposed is not coming through. I think people just kind of get fed up and they just lose their faith in the entire thing and its ability to deliver on what it was supposed to. And I think that can have pretty severe long-term implications to the success. It’s hard to right that ship once you’ve gone in that direction.
Kara Van Malssen: 55:10
So time is important as a factor, but I’m also reading into what you just said that the duration when it lags or it takes an exceptionally long time could also be a symptom of a larger problem, it sounds like.
Chris Lacinak: 55:25
– Yeah, I think it is a symptom of a larger problem. The problem is you didn’t have a strategy.
Kara Van Malssen: 55:30
Right.
Chris Lacinak: 55:31
So you didn’t have kind of a clear point of focus, clear use cases you’re prioritizing, ’cause that’s the key point is, what use cases are you gonna solve for in what order? It doesn’t mean solve for all of them at once. If we have five main use cases, and these are pretty high level, they can be pretty big, doesn’t mean do them all at once. It means they’re sequenced in a way. So you start to deliver benefits and value to those use cases in a sequence, in an order, and they should be sequenced in such a way that each one lays a foundation for the next. So each subsequent one you solve for isn’t like starting from zero. You’ve already got with the first use case, you’ve created a layer. And by the time you get to the end of all those use cases, you’ve solved for 80% of the needs that that particular strategy is solving for. What tends to happen in cases where it takes way too long, some cases, they just really don’t know what goes into setting up, implementing, and making decisions around the DAM. And so that can just stall things. But even if you are more aware and you kind of do understand what’s gonna go into that, that’s the case where I just see people taking on way too much.
Kara Van Malssen: 56:49
Well, Kara, I wanna thank you so much for joining me today. I think I’m really excited about people hearing this and putting the canvas to use. I wanna end with one final question that I ask all of the guests on the DAM Right podcast. And it’s totally different than having to do with the strategy conversation. And that is, what is the last song that you added to your favorites playlist or liked?
Chris Lacinak: 57:17
Well, I’m gonna have to say that there is a difference between my like songs and my favorites because my son who’s eight years old rules the like songs playlist. That is his playlist. So I won’t tell you what the last song that was added to that. My personal playlist of favorites, well, it’s been a little while since I added a song, but kind of maybe earlier, a little mid to last year was the last time I put a song onto it, sadly. But it was “Kandy” by Fever Ray. And they’re a Swedish pop electro artist that used to be part of the duo, The Knife, in the earlier 2000s. And this is their solo act as Fever Ray. And the song “Kandy”, that was like the last song that really kind of got under my skin and I couldn’t stop listening to. So that’s the last one on the playlist.
Kara Van Malssen: 58:14
All right, so listeners go find it and pump it up while you start working on your DAM Strategy Canvas. It’ll be a good soundtrack to it.
Chris Lacinak: 58:23
No, don’t think that’s the right sound.
Kara Van Malssen: 58:25
Okay, well, what, all right.
Chris Lacinak: 58:27
If it works for you, don’t worry.
Kara Van Malssen: 58:28
Here’s a question. Give us a soundtrack, a song that would be good for filling out the DAM Strategy Canvas.
Chris Lacinak: 58:35
All right, good question. When I was making it, I was listening to a lot of The Isley Brothers and things like that. So maybe give you some good energy, good vibes.
Kara Van Malssen: 58:48
All right, interesting. Sounds good. Awesome, well, thank you so much for joining me today, Kara. It’s been super fun and I’m really excited about folks being able to hear this. Thank you so much, really appreciate it.
Chris Lacinak: 58:59
Yeah, thanks for having me. And if folks have any questions or feedback about the DAM Strategy Canvas, then reach out, let us know.
Kara Van Malssen: 59:06
Great, I’ll put that contact info in the show notes. All right, talk to you soon, bye-bye.
Chris Lacinak: 59:12
Okay.
Kara Van Malssen: 59:15
You might be listening to this episode and thinking this sounds awesome, but how can I do this for myself? Lucky for you, you can download AVP’s DAM Strategy Canvas for free at weareavp.com/free-resources. That’s weareavp.com/free-resources. The DAM Strategy Canvas is your roadmap to creating the perfect DAM strategy all on one page. If you’re enjoying the DAM Right podcast, please rate, like, follow, subscribe on your podcast platform of choice. And stay up to date with me and the DAM Right podcast on LinkedIn at linkedin.com/in/clacinak. That’s linkedin.com/in/clacinak. (upbeat music) [ Silence ]
An Interview with Kara Van Malssen on the DAM Operational Model
14 February 2023
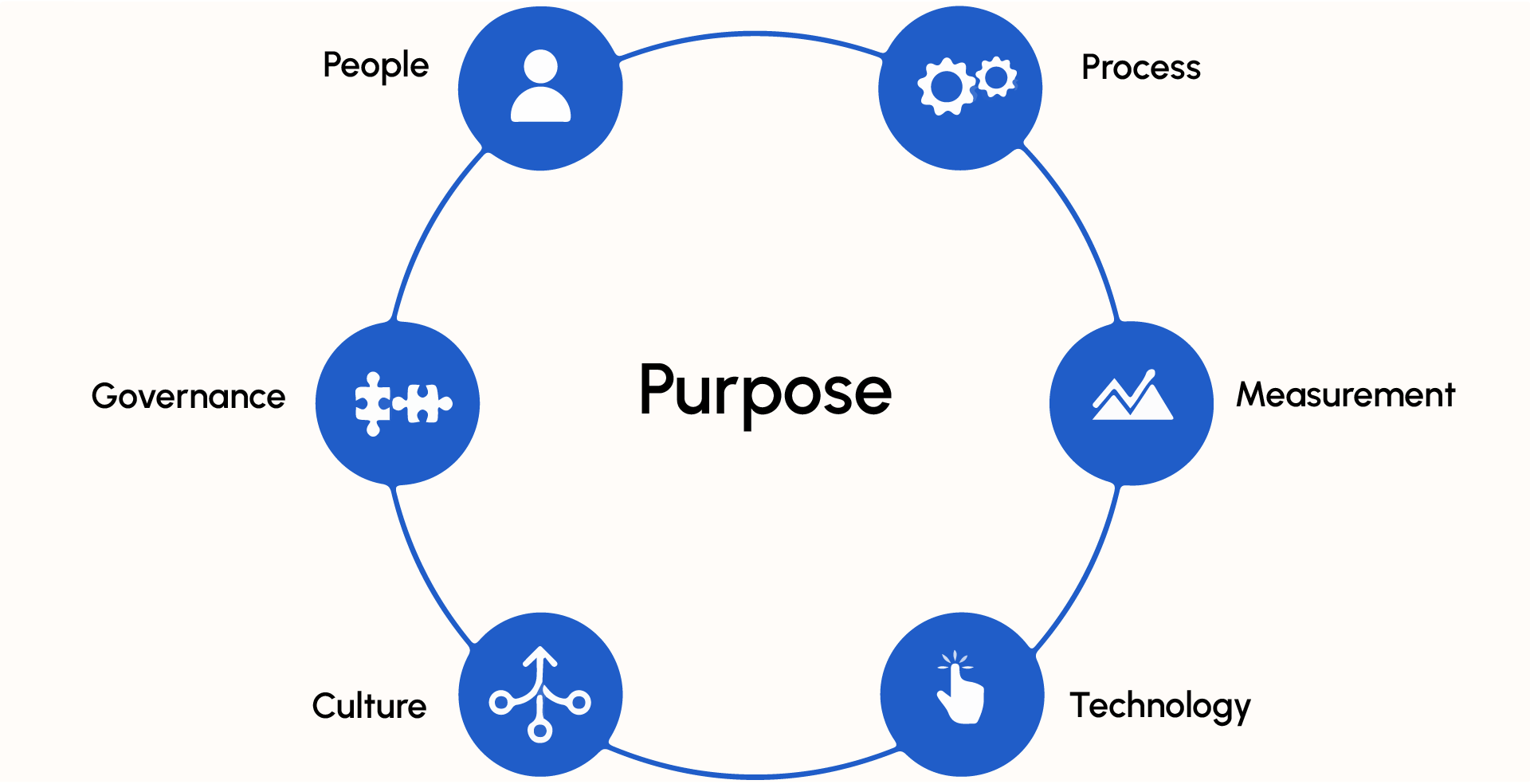
AVP recently published AVP’s Operational Model for DAM Success, authored by Kara Van Malssen. This operational model, pictured to the right, is a thorough, holistic look at what it takes to launch and sustain a healthy and successful digital asset management program. The video below is an interview with Kara Van Malssen about the DAM Operational Model from the creator’s perspective.
Topics in this interview include:
- Inspiration and background behind the DAM Operational Model
- How to think about implementing the DAM Operational Model
- The target audience for this model and who it will work for
- Whether this model is only for DAM, or if it also works for MAM, PAM, digital preservation, etc.
- Why leadership should care about, and invest in, getting digital asset management right
- The costs of getting digital asset management wrong
- Why each of the components are important and how we should think about them within the model:
- Purpose
- People
- Governance
- Technology
- Process
- Measurement
- Culture
- How AVP uses the DAM Operational Model in our work every day
- What’s next for the DAM Operational Model
AVP Tips to Manage Your DAM Expectations Video
2 July 2020
AVP DAM System Specialists Kara Van Malssen and Kerri Willette talk through tips on how to manage expectations during a DAMS launch. The tips are from a recent AVP blog post Manage Your DAM Expectations and based on Van Malssen’s white paper Scenario Planning for a Successful DAM Journey.
How to Aviary: Lesson 3
17 June 2019
How to Create and Configure a Collection
Lesson3, Part 1: How to Create a Collection
Lesson 3, Part 2: How to Configure a Collection
Managing Data In Spreadsheets
8 June 2019
In this tutorial, spreadsheets are positioned as a mechanism to help practitioners manage metadata more accurately, efficiently, and effectively. There are many opportunities to leverage sophisticated features in spreadsheet applications that allow you to work faster, smarter, and with greater accuracy towards a more robust metadata management system. The tutorial features instruction using Microsoft Excel. Self-directed exercises and practices worksheets are linked here:
How To Aviary: Lesson 2
22 April 2019