ai
The DAM AI Gap Is Real. Here’s How to Close It.
15 January 2026
The fastest way to tell if your DAM is (un)healthy is to turn on AI.
Because AI does not just make DAM smarter. It makes your DAM’s foundations visible. When the fundamentals are strong, AI accelerates what is already working. When the fundamentals are weak, AI amplifies inconsistency, risk, and cleanup work.
That matters because organizations are being asked to do more with less, and AI has become the default answer. DAM is no longer expected to be a repository. It’s expected to orchestrate content operations, reduce friction, and scale output. But without consistent metadata, clear governance, and operational control, AI can’t deliver that promise. It amplifies whatever is already true in your DAM, including gaps.
AI is proliferating across the DAM ecosystem. Vendors and DAM-adjacent platforms are shipping automated metadata creation, natural language search, and agentic AI at an unprecedented pace. Leaders within organizations are being told to expect dramatic gains in efficiency, automation, and discoverability, often framed as the fastest path to doing more with less.
But a consistent reality is showing up across organizations: many do not yet have the foundations, funding, or control required to leverage AI safely and effectively.

This is what I’m calling the DAM AI Gap: the disconnect between what AI promises and what most DAM programs are actually ready to operationalize.
If you are not seeing results from your DAM or early AI initiatives, it is likely not a technology problem. It is a foundation problem.
The good news is that this gap is solvable and often faster to address than leaders expect when the work is approached with the right experience and a clear path.
The Gap
The pattern is straightforward. Market innovation is moving faster than organizational readiness. Advanced AI capabilities assume a level of maturity that many DAM programs have not yet achieved. Most organizations are still constrained by fundamentals:
- Inconsistent or missing metadata
- Weak or unclear governance and ownership
- No taxonomy or competing taxonomies
- Fragile workflows and uneven adoption
- Half-baked integrations that keep content scattered across systems and shared drives
- Disorganized ecosystem
The ambition is DAM as a system of action, not storage. The reality is uneven data quality, under-resourced teams, and unclear control points. The risk is that AI and automation amplify weakness rather than resolve it.
AI does not replace DAM fundamentals, it depends on them. When the underlying structures are not in place, AI-driven features often create new failure modes. Improved discoverability without strong permissions and rights management can expose content to the wrong audiences.
Automation without oversight can scale mistakes faster than teams can catch them. AI layered onto fragile governance can create noise and unpredictability, which erodes trust and adoption.
In our 2026 DAM Trends survey, the tension was clear: the vision is compelling, but the fear is being pushed to move faster than governance, data quality, and operational control can support.
Most organizations are operating under sustained efficiency pressure. DAM, marketing operations, and content operations teams are being asked to deliver more impact with constrained capacity while also adopting new AI-driven capabilities.
In that environment, the foundational work AI requires is often the first work deferred. Metadata models, taxonomy decisions, governance structures, rights and permission frameworks, workflow integrity, integration design, enablement and operational ownership are hard to prioritize when teams are stretched.
The result is predictable: the organization invests in AI and automation expecting speed and savings, but experiences more cleanup work, higher risk exposure, and slower adoption. Not because the technology failed, but because the operating foundation was never built to support it and accordingly there were unreal expectations of what AI could do.
This is not a story about resistance to change. It is a story about organizations knowing what DAM needs to become and being acutely aware of what can go wrong if they try to get there without fixing the fundamentals.
Closing the Gap and Delivering on the Promise of AI
At AVP, we embrace the potential of AI, but our stance is grounded in truth and readiness.
AI can amplify DAM value, but only when the foundations are sound. If you want to unlock the power of AI, you have to get the foundation in place first. Much of that foundation is what we define as the DAM Operational Model: the operating system that makes DAM sustainable and scalable across people, process, governance, and technology (Learn more about that here.)

Without it, AI becomes another layer of activity on top of instability, rather than a multiplier of value.
This includes things like:
- A metadata model and taxonomy aligned to how the business finds, governs, and uses content
- Clear governance, ownership, and operating mechanisms that sustain quality over time
- Permissions, rights management, and policy controls that protect the organization as discoverability improves
- Workflows and practices that scale across teams and regions
- Integrations that support end-to-end operations, not isolated repositories
When these fundamentals are in place, the outcomes leaders are looking for become achievable:
- AI works as intended
- Automation becomes reliable
- Rights and intellectual property are protected
- Workflows scale and cycle times drop
- Adoption increases because teams trust the system
- ROI becomes visible and defensible
If your organization is under pressure to move faster with AI, the highest-leverage move is to treat DAM fundamentals as an executive-level capability, not an operational nice-to-have.
That framing also gives DAM practitioners the language they need internally: the work is not “cleanup.” It is risk mitigation, preparedness, efficiency enablement, and value realization. The goal is not to slow down AI. The goal is to make AI safe and effective.
AVP helps organizations close the DAM AI Gap by building the foundation required to make AI safe, scalable, and ROI-driving. We provide the expertise and capacity to:
- Build or rebuild taxonomy and metadata structures
- Establish governance, permissions, and rights management
- Fix workflow and operational bottlenecks
- Stabilize underperforming DAM environments
- Support lean or capacity-constrained teams
- Integrate AI safely and effectively
If you are not seeing the results you expected from DAM or early AI initiatives, start with readiness. Close the foundational gaps that determine whether AI becomes a multiplier or a liability.
Work with AVP to build the DAM foundation that enables safe deployment, scalable operations, and defensible ROI.
DAM delivers on the promise of AI. AVP delivers on the promise of DAM.
Let us know how we can help you.
Trust, Authenticity & Governance for the AI Age
1 December 2025
Trust is hard to come by.
Eminem
Technology succeeds when it is leveraged to transform data into information and then information into insight that can then generate action and meaning. Collective actions build mutual trust among community members, establishing knowledge-sharing opportunities, lowering transaction costs, resolving conflicts, and creating greater coherence. Trust sets expectations for positive future interactions and encourages participation with technology. Communicating the meaning and purpose of why a technology tool is being used will build trust with its audience and impact positive experiences. Trust in technology and the data flowing through all connected systems will lead to greater participation that will increase information’s value and utility. But is artificial intelligence (AI) in our content, our documentation, and our marketing information is making this all the messier and more complicated? The question is, do we trust what we see and read?
AI as an energetic force for change in our modern business content systems such as a DAM, PIM, CMS, and e-Commerce will accelerate the conversation between business and consumer. All the integration and interconnectivity between business applications strengthens the argument for strong and authoritative metadata, and for effective workflow management. Businesses creating and disseminating brand and marketing messages and products will engage with the consumer community who will respond with shopping behavior, internet searches, assets, and data such as reviews, comments, images, check-ins and other online actions. Data serving content as a connection between people, process, and technology.
Furthermore, understanding the needs of users and showing transparency in the technology, the people and the process will improve the experience and start the path to building trust. And yet, trust is hard to come by because there is not enough of it in our data. It’s no surprise that some of the biggest and most vocal critics of AI are artists themselves, the creators, those who create from an original and inspired source.
“I hate AI … AI is the world’s most expensive and energy-intensive plagiarism machine. I think they’re selling a bag of vapor.” – Vince Gilligan
“People ask if I’m worried about artificial intelligence, I say I’m worried about natural stupidity?” – Guillermo del Toro
And we are beginning to see more criticism from the creative community of AI being used in marketing the most recent of which is the negative feedback on Coca-Cola’s 2025 Christmas ad which follows criticism of their 2024 efforts. This in tandem with the persistence of “AI hallucinations” gives us all reason to pause and query where the trust and authenticity is in our content. Should consumers be skeptical … yes, but if we start to “distrust” what we see, then uncertainty creeps into the relationship. A 2024 study by Bynder found that when posts sound AI-written, 25% of people think the brand feels impersonal, and others flat-out call it lazy. Trust is getting harder to come by in a world filled more with hyperbole than facts, precision and nuance.
Let’s get some definitions out of the way to help both ground and illuminate this discussion:
Authenticity – The trustworthiness of a record as a record, i.e., the quality of a record that is what it purports to be and that is free from tampering or corruption.
Provenance – The origin or source of something. Information regarding the origins, custody, and ownership of an item or collection.
Integrity – The quality of being honest and having strong moral principles; of being whole and complete.
Data Integrity – The property that data has not been altered in an unauthorized manner; in storage, during processing, and while in transit.
What’s your data-driven AI strategy? We want the data and the machines managing it to learn and do more, but we must provide them with good, quality data for them to do that. Good data = smart data = good learning = happy customers. But if the data delivered does not match the user expectations, then the efficiencies of a personalized, and meaningful consumer experience are lost. Do we trust what we see and read? Data is the foundation for all that organizations do in business and how they interact with their customers. Data is proliferating, and that growth is only going to continue exponentially. As it multiplies, organizations need refreshed, enterprise-level approaches to systematically create, distribute, and manage data for your brand and your customers. Is authentic, accurate, and authoritative data the foundation to help us navigate the digital age?
Information Integrity
“Transparency builds trust.”
Denise Morrison
Data provides the link allowing processes and technology to be optimized. But if the data delivered does not match the user expectations of accuracy and authenticity, trust may be lost. Trust may not always be built with consistency if the facts are not always there. Be mindful of the current situation and the challenges faced. More importantly, be mindful of the people, processes, and technologies that may influence transformation. Information, IP and content are critical to business operations; they need to be managed at all points of a digital life cycle. Trust and certainty that data is accurate and usable is critical. Leveraging meaningful metadata in contextualizing, categorizing and accounting for data provides the best chance for its return on investment. The digital experience for users will be defined by their ability to identify, discover, and experience an organization’s brand just as the organization has intended.
Integrity of information means it can be trusted as authentic and current. When content is allowed to move freely, the chain of custody can be lost, undermining trust that the information is original. By establishing rules around originality and custodianship, or document ownership, content can be relied on as the “single source of truth,” and there may well be more than one source of truth, for it is authenticity we seek. As an example, if we define content as something that has value to the organization, then controls should be placed on access to that content. If controls are not in place, or they are insufficient, then the consequences can be embarrassing and costly. Possible dangers might include having the company sustain damage to its reputation, or it could result in the loss of trust of clients or consumers.
History teaches us that the study of “Diplomatics” in Archival Studies, posits that a document is authentic when it is what it claims to be. The Society of American Archivists (SAA) definition reads, “The study of the creation, form, and transmission of records, and their relationship to the facts represented in them and to their creator, in order to identify, evaluate, and communicate their nature and authenticity.” And, with that definition comes arguably its greatest modern proponent of Diplomatics, Luciana Duranti, reminds us to be mindful of, “the persons, the concepts of function, competence, and responsibility” must all be considered when considering digital assets and trust, from creation to distribution. Trust in content created with authority, authenticity, and responsibility.
Governance is No Longer an Option
Governance is the process that holds your organization’s data operations together as you seek to become truly data-driven, realize the full value of your data and content, and avoid costly missteps. To be effective, governance must be considered as a holistic corporate objective establishing policies, procedures, and training for the management of data across the organization and at all levels. Without governance, opportunities to leverage enterprise data and ultimately your content to respond to new opportunities may be lost. By developing a project charter, working committee, and timelines, governance becomes an ongoing practice to deliver ROI, innovation, and sustained success. While technology is important, culture will prevail, for Governance is more than just “change management”. Governance demands a cultural presence and footprint. The best way to plan for change is to apply an effective layer of governance to your program.
In his autobiography, Permanent Record, Edward Snowden argues that “Technology doesn’t have a Hippocratic oath. So many decisions that have been made by technologists in academia, industry, the military, and government since at least the Industrial Revolution have been made based on ‘can we,’ not ‘should we.” Another example of governance is needed is reflected in the advice of moving away from the brash work ethic of “move fast and break things,” from millennial technobrat and Cambridge Analytica whistleblower Christopher Wylie, who argues for a “building code for the internet” and a “code of ethics”—in essence, regulations to prevent the technological atrocities of the past. Governance is about the ability to enable strategic alignment, to facilitate change, and maintain structure amidst the perceived chaos.
Good governance delivers innovation and sustained success by building collaborative opportunities and participation from all levels of the organization. The more success you have in getting executives involved in the big decisions, keeping them talking about AI making this a regular, operational discussion (not just for project approval or yearly budget reviews), the greater the benefits your organization will have. Participation from all levels of the organization is key. Engaging the leadership by involving them in the big decisions, holding regular reviews and keeping them talking about DAM or any content management system, will yield the greatest benefits.
Opportunities to Provide Authenticity
From a legal point of view, there is some hope for the future as new legislation regarding AI creation and usage does take into account issues of “transparency” and “provenance,” most notably in the new California Transparency Act (AB 853) (SB 942), and the Transparency in Frontier Artificial Intelligence Act (TFAIA) all coming into effect in 2026, with the EU Artificial Intelligence Act been in place since 2024.
From a practical point of view, there are some things we as digital creators and managers of content may do:
- C2PA, Coalition for Content Provenance and Authenticity, provides an open technical standard for publishers, creators and consumers to establish the origin and edits of digital content at the metadata level. This also includes Content Credentials to leave a metadata audit trail for your digital assets (e.g. date, time, and location of creation, along with a digital signature to prove authenticity)
- Employ embedded digital signatures and watermarking.
- Implement AI detection to identify if an image, video, or audio file has been altered or generated by AI.
- Quality control and data verification on a regular basis throughout the digital asset life cycle to ensure content came from trusted and authorized sources.
- Governance as an organizational process to mitigate risk and to achieve your goals.
Amidst the clash and clatter of AI it is good to know there are real tangible things you can start doing to use people, process, technology and data to navigate this complex environment.
Conclusion
Good, trusted, authentic data is critical to AI; trust and certainty that the data is accurate and usable is critical for success. And be mindful of the people, processes, and technologies that may influence data and learning within business. Data will only continue to grow. There has never been a more important time to make data a priority and to have a road map for delivering value from it. AI provides great opportunities for communication, engagement, and risk management. Data sharing and collaboration will play an important part in growth, as business rules and policies will govern the ability to collect and analyze internal and external data. More importantly, business rules will govern an organization’s ability to generate knowledge—and ultimately value. To deliver on its promise, data must be delivered consistently, with standard definitions, and organizations must have the ability to reconcile data models from different systems.
A call to action … may we all just slow down. Simple, and effective. Yes, AI is incredible and powerful and advancing at a fast pace, which is exactly why we need to slow down as best as we can. Remember to evaluate your trusted sources of information and evaluate what you are reading. Trust may not always be built with consistency if the facts are not always there. Be mindful of the current situation and the challenges faced. More importantly, be mindful of the people, processes, and technologies that may influence transformation. Information, IP and content are critical to business operations; they need to be managed at all points of a digital life cycle. Trust and certainty that data is accurate and usable is critical. Leveraging meaningful metadata in contextualizing, categorizing and accounting for data provides the best chance for its return on investment. The digital experience for users will be defined by their ability to identify, discover, and experience an organization’s brand just as the organization has intended.
While metadata may help us find the facts needed for that truth, governance is the structure around how organizations manage content creation, use, and distribution and a critical part to developing trust. Ultimately, governance is the structure enabling content stewardship, beginning with metadata and workflow strategy, policy development, and more, and technology solutions to serve the creation, use, and distribution of content. Content does not emerge fully formed into the world. It is products of people working with technology in the execution of a process… the transparency needed for content to be authoritative, authentic, and all willing, responsible. Trust may be built through transparency and quality data, and trust may be earned through good governance; your brand depends upon it.
Citations
- https://variety.com/2025/tv/news/pluribus-explained-vince-gilligan-rhea-seehorn-1236571666
- https://www.hollywoodreporter.com/movies/movie-news/guillermo-del-toro-not-worried-artificial-intelligence-1235585785/
- https://www.creativebloq.com/design/advertising/what-brands-can-learn-from-coca-colas-terrible-ai-christmas-ad
- https://www.bynder.com/en/press-media/ai-vs-human-made-content-study/
- https://interparestrustai.org/terminology/term/authenticity
- https://dictionary.archivists.org/entry/provenance.html
- https://dictionary.cambridge.org/us/dictionary/english/integrity
- https://csrc.nist.gov/glossary/term/data_integrity
- https://calmatters.digitaldemocracy.org/bills/ca_202520260ab853
- https://calmatters.digitaldemocracy.org/bills/ca_202320240sb942
- https://www.gov.ca.gov/2025/09/29/governor-newsom-signs-sb-53-advancing-californias-world-leading-artificial-intelligence-industry/
- https://artificialintelligenceact.eu/
Getting Started with AI for Digital Asset Management & Digital Collections
13 October 2023
Talk of artificial intelligence (AI), machine learning (ML), and large language models (LLMs) is everywhere these days. With the increasing availability and decreasing cost of high-performance AI technologies, you may be wondering how you could apply AI to your digital assets or digital collections to help enhance their discoverability and utility.
Maybe you work in a library and wonder whether AI could help catalog collections. Or you manage a large marketing DAM and wonder how AI could help tag your stock images for better discovery. Maybe you have started to dabble with AI tools, but aren’t sure how to evaluate their performance.
Or maybe you have no idea where to even begin.
In this post, we discuss what artificial intelligence can do for libraries, museums, archives, company DAMs, or any other organization with digital assets to manage, and how to assess and select tools that will meet your needs.

Examples of AI in Libraries and Digital Asset Management
Wherever you are in the process of learning about AI tools, you’re not alone. We’ve seen many organizations beginning to experiment with AI and machine learning to enrich their digital asset collections. We helped the Library of Congress explore ways of combining AI with crowdsourcing to extract structured data from the content of digitized historical documents. We also worked with Indiana University to develop an extensible platform for applying AI tools, like speech-to-text transcription, to audiovisual materials in order to improve discoverability.
What kinds of tasks can AI do with my digital assets?
Which AI methods work for digital assets or collections depends largely on the type of asset. Text-based, still image, audio, and video assets all have different techniques available to them. This section highlights the most popular machine learning-based methods for working with different types of digital material. This will help you determine which artificial intelligence tasks are relevant to your collections before diving deep into specific tools.
AI for processing text – Natural Language Processing
Most AI tools that work with text fall under the umbrella of Natural Language Processing (NLP). NLP encompasses many different tasks, including:
- Named-Entity Recognition (NER) – NER is the process of identifying significant categories of things (“entities”) named in text. Usually these categories include people, places, organizations, and dates, but might also include nationalities, monetary values, times, or other concepts. Libraries or digital asset management systems can use named-entity recognition to aid cataloging and search.
- Sentiment analysis – Sentiment analysis is the automatic determination of the emotional valence (“sentiment”) of text. For example, determining whether a product review is positive, negative, or neutral.
- Topic modeling – Topic modeling is a way of determining what general topic(s) the text is discussing. The primary topics are determined by clustering words related to the same subjects and observing their relative frequencies. Topic modeling can be used in DAM systems to determine tags for assets. It could also be used in library catalogs to determine subject headings.
- Machine translation – Machine translation is the automated translation of text from one language to another–think Google Translate!
- Language detection – Language detection is about determining what language or languages are present in a text.

AI for processing images and video – Computer Vision
Using AI for images and videos involves a subfield of artificial intelligence called Computer Vision. Many more tools are available for working with still images than with video. However, the methods used for images can often be adapted to work with video as well. AI tasks that are most useful for managing collections of digital image and video assets include:
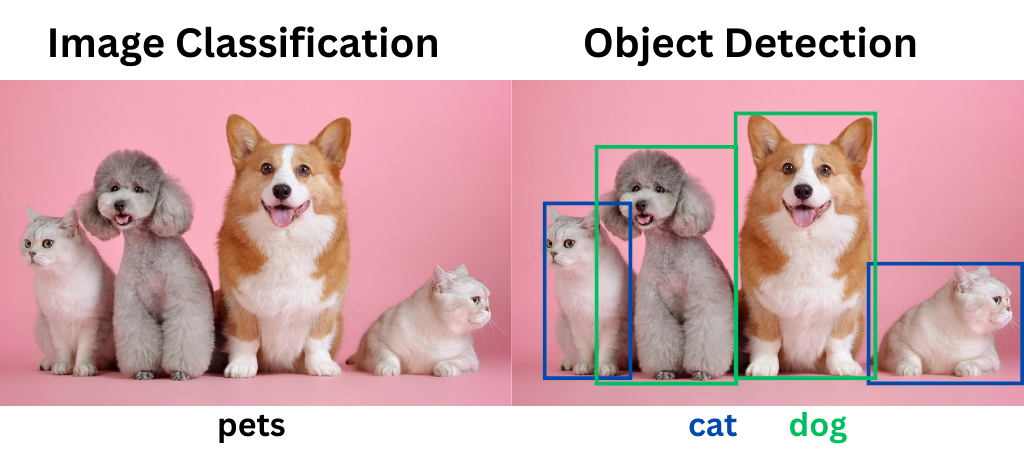
- Image classification – Image classification applies labels to images based on their contents. For example, image classification tools will label a picture of a dog with “dog.”
- Object detection – Object detection goes one step further than image classification. It both locates and labels particular objects in an image. For example, a model trained to detect dogs could locate a dog in a photo full of other animals. Object detection is also sometimes referred to as image recognition.
- Face detection/face recognition – Face detection models can tell whether a human face is present in an image or not. Face recognition goes a step further and identifies whether the face is someone it knows.
- Optical Character Recognition (OCR) – OCR is the process of extracting machine-readable text from an image. Imagine the difference between having a Word document and a picture of a printed document–in the latter, you can’t copy/paste or edit the text. OCR turns pictures of text into digital text.
AI for processing audio – Machine Listening
AI tools for working with audio are much fewer and farther between. The time-based nature of audio, as opposed to more static images and text, makes working with audio a bit more difficult. But there are still methods available!
- Speech-to-text (STT) – Speech-to-text, also called automatic speech recognition, transcribes speech into text. STT is used in applications like automatic caption generation and dictation. Transcripts created with speech-to-text can be sent through text-based processing workflows (like sentiment analysis) for further enrichment.
- Music/speech detection – Speech, music, silence, applause, and other kinds of content detection can tell you which sounds occur at which timestamps in an audio clip.
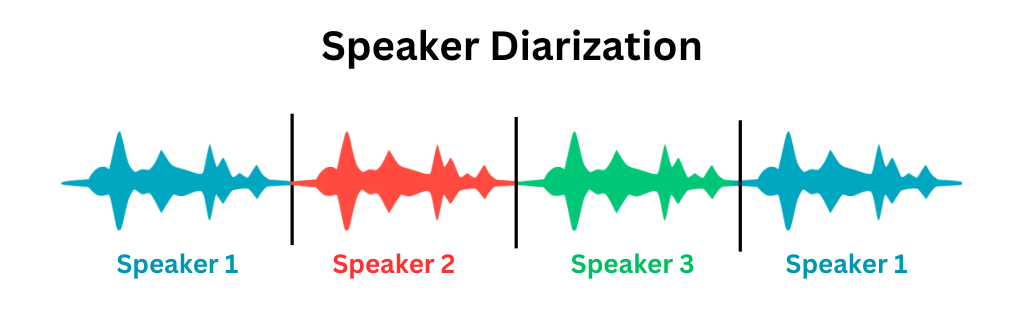
- Speaker identification / diarization – Speaker identification or diarization is the process of identifying the unique speakers in a piece of audio. For example, in a clip of an interview, speaker diarization tools would identify the interviewer and the interviewee as speakers. It would also tell you where in the audio each speaks.
What is AI training, and do I need to do it?
Training is the process of “teaching” an algorithm how to perform its task.
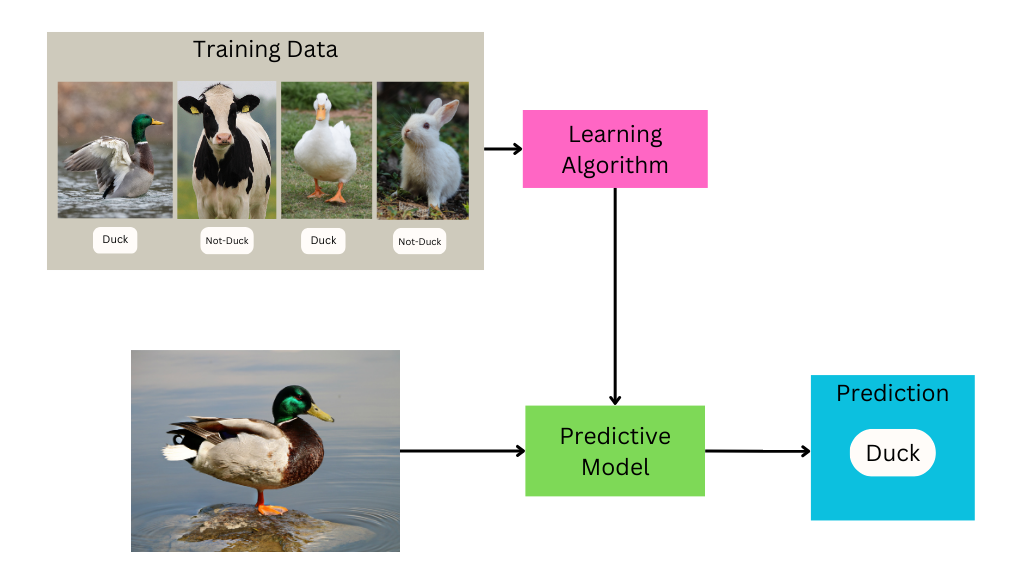
Creating a trained machine learning model involves developing a set of training data, putting that data through a learning algorithm, and tweaking parameters until it produces desirable results.
You can think of training data as the “answer key” to a test you want the computer to take.
For example, if the task you want to perform is image classification–dividing images into different categories based on their contents–the training data will consist of images labeled with their appropriate category. During the training process, the computer examines that training data to determine what features are likely to be found in which categories, and subsequently uses that information to make guesses about the appropriate label for images it’s never seen before.
In addition to the labeled data given to the algorithm for learning, some data has to be held back to evaluate the performance of the model. This is sometimes called “ground truth” testing, which we’ll discuss more below.
Developing training and testing data is often the most time-consuming and labor-intensive part of working with machine learning tools. Getting accurate results often requires thousands of sample inputs, which may (depending on the starting state of your data) need to be manually processed by humans before they can be used for training.
Training AI tools sounds costly, is it always necessary?
Custom training may not be required in all cases. Many tools come with “pre-trained” models you can use. Before investing loads of resources into custom training, determine whether these out-of-the-box options meet your quality standards.
Keep in mind that all machine learning models are trained on some particular set of data.
The data used for training will impact which types of data the model is well-suited for—for example, a speech-to-text model trained on American English may struggle to accurately transcribe British English, and will be completely useless at transcribing French.
Researching the data used to train out-of-the-box models, and determining its similarity to your data can help set your expectations for the tool’s performance.
Choose the right AI tool for your use case

Before you embark on any AI project, it’s important to articulate the problem you want to solve and consider the users that this AI solution will serve. Clearly defining your purpose will help you assess the risks involved with the AI, help you measure the success of the tools you use, and help you determine the best way to present or make use of the results for your users in your access system.
All AI tools are trained on a limited set of content for a specific use case, which may or may not match your own. Even “general purpose” AI tools may not produce results at the right level of specificity for your purpose. Be cautious of accuracy benchmarks provided by AI services, especially if there is little information on the testing process.
The best way to determine if an AI tool will be a good fit for your use case is to test it yourself on your own digital collections.
How to evaluate AI tools
Ground truth testing is a standard method for testing AI tools. In ground truth testing, you create examples of the ideal AI output (ground truth) for samples of your content and check them against the actual output of the AI to measure the tool’s accuracy.
For instance, comparing the results of an object recognition tool against the list of objects you expect the tool to recognize in a sample of images in your digital asset management system can show you the strengths of the AI in correctly identifying objects in your assets (true positives) and its weaknesses in either not detecting objects it should have (false negatives) or misidentifying objects (false positives).
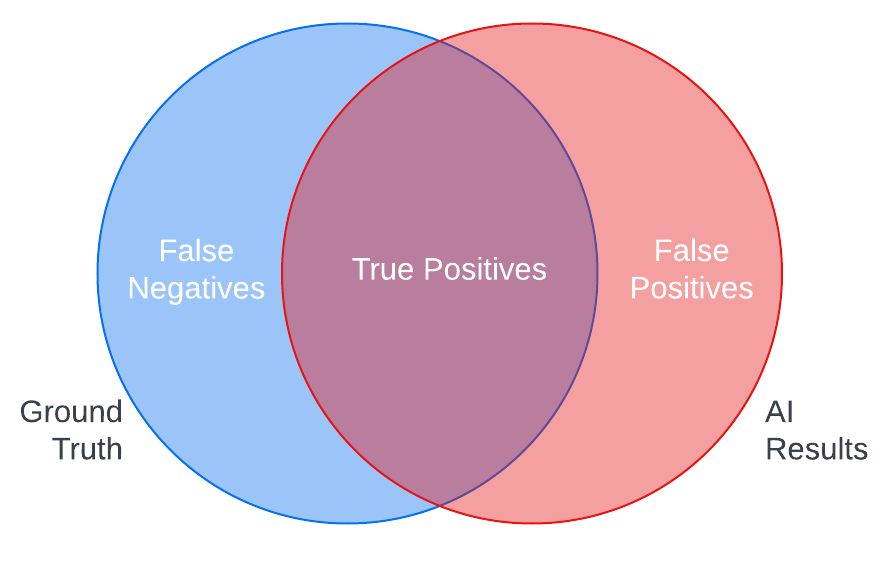
Common quantitative measures for ground truth testing include precision and recall, which can help you better calculate these risks of omission and misidentification. You can also examine these errors qualitatively to better understand the nature of the mistakes an AI tool might make with your content, so you can make informed decisions about what kind of quality control you may need to apply or if you want to use the tool at all.
Ground truth testing, however, can be costly to implement.
Creating ground truth samples is time-consuming, and the process of calculating comparison metrics requires specialized knowledge. It’s also important to keep in mind that ground truth can be subjective, depending on the type of tool—the results you’d expect to see may differ in granularity or terminology from the outputs the AI was trained to produce.
In the absence of ground truth, you can visually scan results for false positives and false negatives to get a sense of what kinds of errors an AI might make on your content and how they might impact your users.
Is it important that the AI finds all of the correct results? How dangerous are false positives to the user experience?
Seeing how AI results align with your answers to questions like these can help to quickly decide whether an AI tool is worth pursuing more seriously.
In addition to the quality of results, it is also important to consider other criteria when evaluating AI tools. What are the costs of the tool, both paid services and staff time needed to implement the tool and review or correct results? Will you need to train or fine-tune the AI to meet the needs of your use case? How will the AI integrate with your existing technical infrastructure?
To learn more about how you can evaluate AI tools for your digital assets with users in mind, check out AVP’s Human-Centered Evaluation Framework webinar, which includes a quick reference guide to these and many other questions to ask vendors or your implementation team.
When not to use artificial intelligence

With all of the potential for error, how can you decide if AI is really worth it? Articulating your goals and expectations for AI at the start of your explorations can help you assess the value of the AI tools you test.
Do you want AI to replace the work of humans or to enhance it by adding value that humans cannot or do not have the time to do? What is your threshold for error? Will a hybrid human and AI process be more efficient or help relieve the tedium for human workers? What are the costs of integrating AI into your existing workflows and are they outweighed by the benefits the AI will bring?
If your ground truth tests show that commercial AI tools are not quite accurate enough to be worth the trouble, consider testing again with the same data in 6 months or a year to see if the tools have improved. It’s also important to consider that tools may change in a way that erodes accuracy for your use case. For that reason, it’s a good idea to regularly test commercial AI tools against your baseline ground truth test scores to ensure that AI outputs continue to meet your standards.
Now what?
The topics we’ve covered in this post are only the beginning! Now that you’ve upped your AI literacy and have a basic handle on how AI might be useful for enhancing your digital assets or collections, start putting these ideas into action.
Learn how AVP can help with your AI selection or evaluation project
Where Do Humans Need To Be In The AI Loop? AVP Case Study
30 October 2021
In 2020 the Library of Congress Labs began the Humans in the Loop experiment to explore ways to responsibly combine crowdsourcing experiences and machine learning workflows. Through a public selection process, AVP was chosen as a project partner to collaboratively develop a framework for ethically, engagingly, and usefully incorporating human feedback via crowdsourcing into training data for machine learning processes. Machine learning’s reliance on pattern recognition and training decisions made by human annotators makes it really good at predicting past classifications. But complexities emerge especially when it comes to the potential to replicate and even proliferate bias and harmful effects. So where do humans need to be in the AI loop?
The project outcomes will provide structure and context for everyone in the machine-learning and libraries communities to better evaluate potential issues that arise through automated, AI-powered metadata enrichment processes. The project is also creating training data constructed with ethical guidelines that can be used by any organization using machine learning to enrich collections description and access. The Humans in the Loop experiment builds directly on LC Labs’ sustained exploration of machine learning in cultural heritage for tasks such as pre-processing, segmentation, classification, clustering, transcription, and extraction.
The team chosen historical Yellow Pages telephone directories that have been digitized for three interactive workflows experiments. Each workflow asked users to draw boxes around ads and text and transcribe highlighted text. The goal was to “teach” the computer how to parse out information from a single digitized page and understand different content types like ads or a directory listing.
Hear some of the Humans in the Loop team discuss how they see the project within an ethical, engaging, and useful context in the video embedded below or stream it here.
VIDEO: Project Discussion: Where Do Humans Need To Be In The AI Loop?
- Dr Meghan Ferriter, Senior Innovation Specialist with the National Digital Initiatives at the Library of Congress
- Natalie Burclaff, Business Reference Specialist, Library of Congress
- Shawn Averkamp, Senior Consultant, AVP
- Kerri Willette, Senior Consultant, AVP